

LLM Deployment: A Strategic Guide from Cloud to Edge
Imagine you have just built a high-performance race car engine (your Large Language Model). It is powerful, loud, and capable […]
LLM Deployment: A Strategic Guide from Cloud to Edge Read More »
Imagine you have just built a high-performance race car engine (your Large Language Model). It is powerful, loud, and capable […]
LLM Deployment: A Strategic Guide from Cloud to Edge Read More »
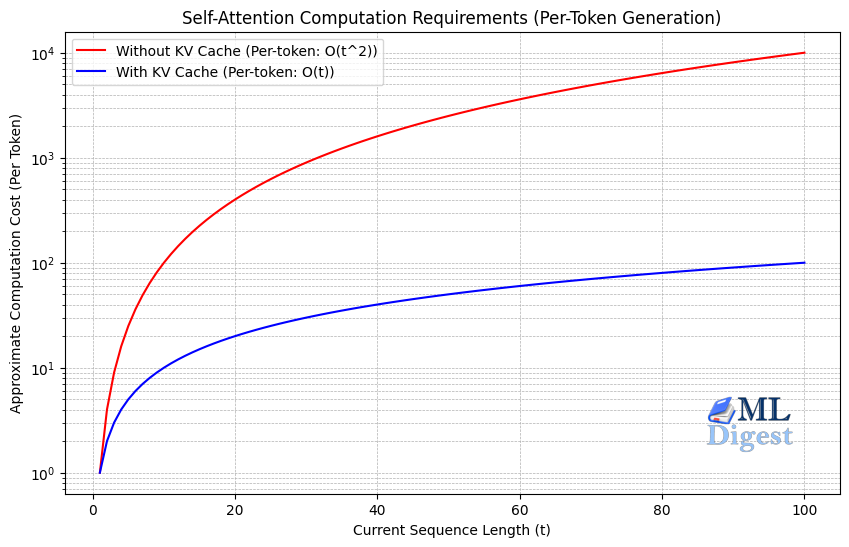
For Large Language Models (LLMs), inference speed and efficiency are paramount. One of the most critical optimizations for speeding up text generation is KV-Caching (Key-Value Caching).
Understanding KV Caching: The Key To Efficient LLM Inference Read More »
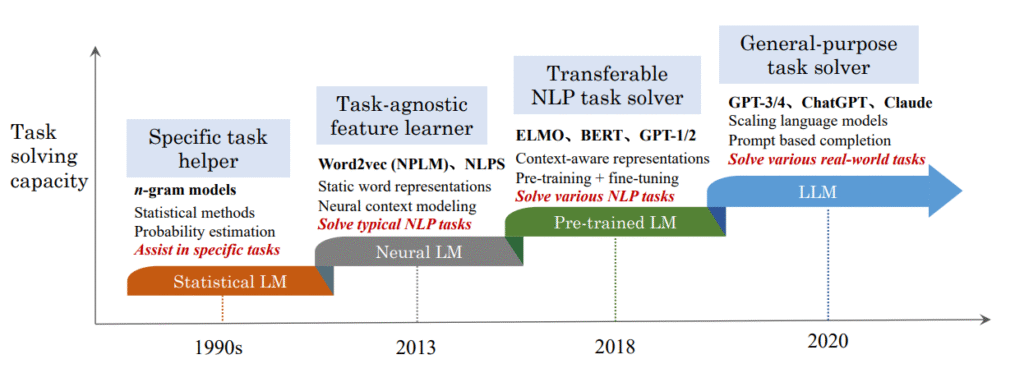
Introduction: The Quest to Understand Language Imagine a machine that could read, understand, and write text just like a human.
How Language Model Architectures Have Evolved Over Time Read More »
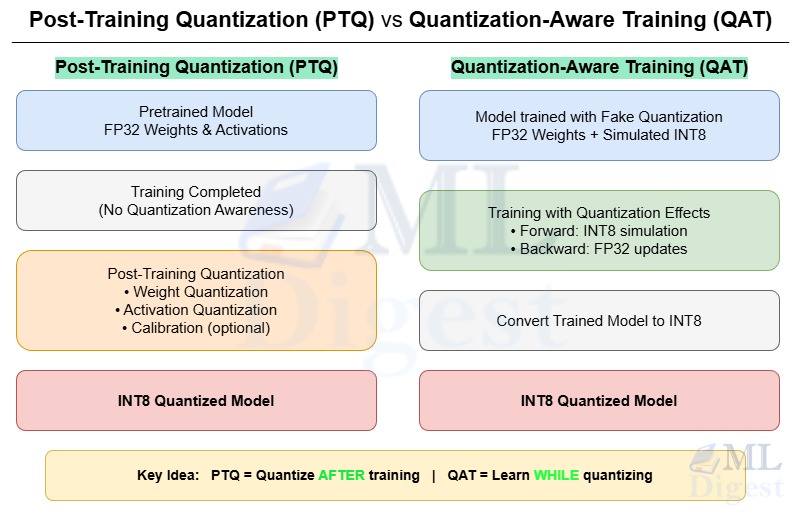
Large deep learning models are powerful but often too bulky and slow for real-world deployment. Their size, computational demands, and
Imagine you are a master artist, renowned for creating breathtaking paintings with an infinite palette of colors. Your paintings are
Quantization-Aware Training: The Best of Both Worlds Read More »
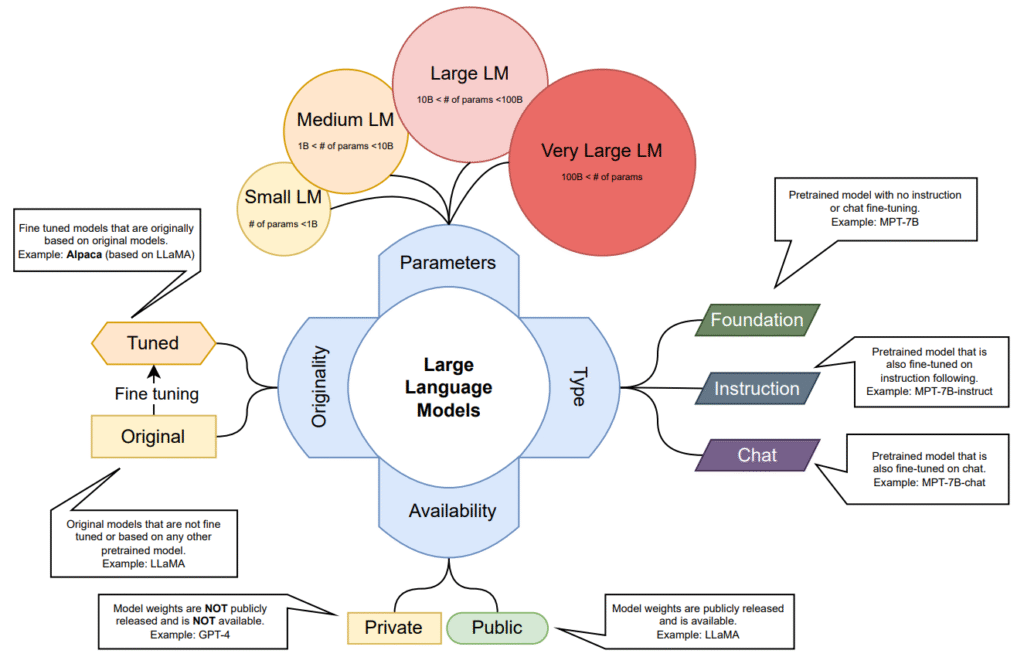
Imagine building a city: at first, you lay simple roads and bridges, but as the population grows and needs diversify,
How Large Language Model Architectures Have Evolved Since 2017 Read More »

As machine learning models grow in complexity and size, deploying them on resource-constrained devices like mobile phones, embedded systems, and
ML Model Quantization: Smaller, Faster, Better Read More »
Large Language Models (LLMs) are computationally expensive to train and deploy. Here are some approaches to reduce their computational cost:
How To Reduce LLM Computational Cost? Read More »