

LLM Deployment: A Strategic Guide from Cloud to Edge
Imagine you have just built a high-performance race car engine (your Large Language Model). It is powerful, loud, and capable […]
LLM Deployment: A Strategic Guide from Cloud to Edge Read More »
Imagine you have just built a high-performance race car engine (your Large Language Model). It is powerful, loud, and capable […]
LLM Deployment: A Strategic Guide from Cloud to Edge Read More »
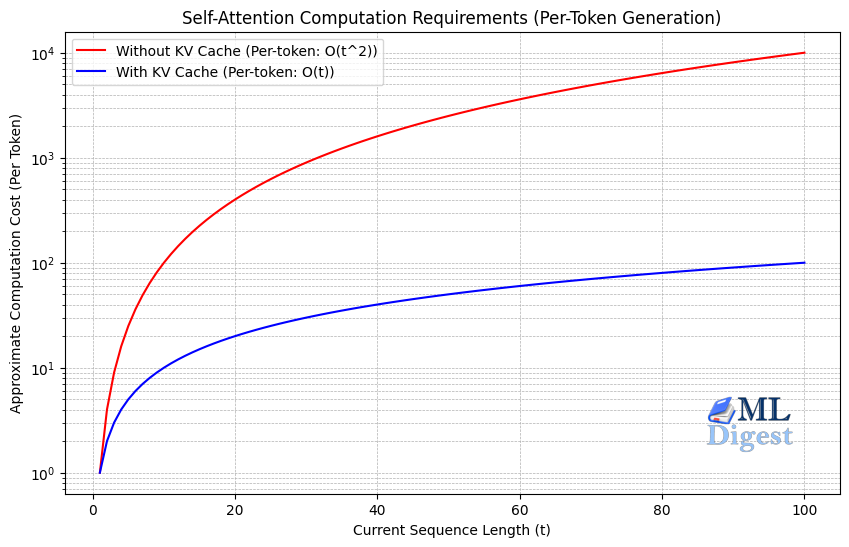
For Large Language Models (LLMs), inference speed and efficiency are paramount. One of the most critical optimizations for speeding up text generation is KV-Caching (Key-Value Caching).
Understanding KV Caching: The Key To Efficient LLM Inference Read More »