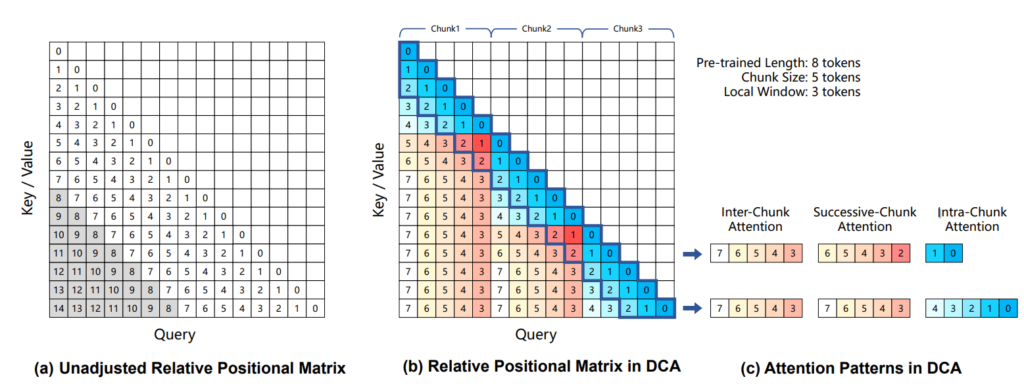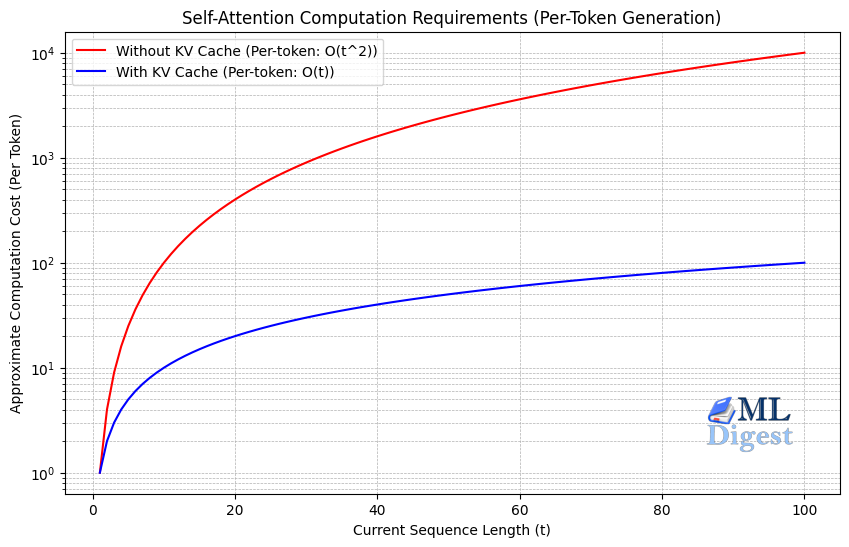
Understanding KV Caching: The Key To Efficient LLM Inference
For Large Language Models (LLMs), inference speed and efficiency are paramount. One of the most critical optimizations for speeding up text generation is KV-Caching (Key-Value Caching).
Understanding KV Caching: The Key To Efficient LLM Inference Read More »