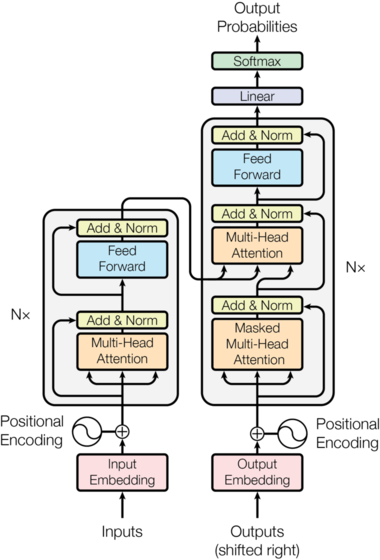
The Qwen2.5-1M series are the first open-source Qwen models capable of processing up to 1 million tokens. This leap in context length allows these models to tackle more complex, real-world scenarios that require extensive information processing or generation.
The Need for Extended Context
Traditional LLMs have been limited by the amount of text they can process at one time. This limitation restricts their ability to handle complex tasks requiring extensive information or long-range dependencies. The limited context window is a drawback in tasks such as:
- Code generation and debugging that relies on repository-level context
- In-depth research based on large volumes of documents
- Comprehending and generating long-range dependencies within text
Models like the GPT series, Llama series, and the earlier Qwen models have rapidly expanded their context windows from 4k or 8k tokens to 128k tokens. There are ongoing explorations to extend these lengths to 1 million tokens or more, such as in Gemini and Llama-3-1M.
The Qwen2.5-1M Series
Open-Source Models
The Qwen2.5-1M series includes two open-source instruction-tuned models: Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M. The “1M” suffix indicates the ability of these models to handle input sequences of up to one million tokens.
API Accessible Model
There is an API-accessible model, Qwen2.5-Turbo, which is based on a Mixture of Experts (MoE) architecture. Qwen2.5-Turbo delivers performance comparable to GPT-4o-mini, while offering longer context and more competitive pricing.
Key Features
The Qwen2.5-1M series incorporates several key features:
- Enhanced Long-Context Capabilities: Significant improvements in handling long-range dependencies and complex information.
- Efficient Inference Framework: An open-sourced inference framework optimized for long-context processing, which allows for cost-effective deployment.
- Length Extrapolation Method: Allows models trained on 256k context lengths to seamlessly scale up to 1M contexts without additional training.
- Sparse Attention Mechanism: Reduces inference costs with optimizations for GPU memory efficiency and improved accuracy.
- Engine-Level Optimizations: Enhancements in kernel performance, pipeline parallelism, and scheduling that boost prefill speeds by 3 to 7 times.
Model Architecture
The Qwen2.5-1M models retain the same Transformer-based architecture as their Qwen2.5 predecessors. The architecture includes several key components:
- Grouped Query Attention (GQA): For efficient KV cache utilization.
- SwiGLU Activation Function: For non-linear transformations.
- Rotary Positional Embeddings (RoPE): To encode positional information.
- QKV Bias: In the attention mechanism.
- RMSNorm with pre-normalization: To ensure stable training.
Training Methodology
Pre-Training
Data and Techniques
The models were pre-trained on an extensive and diverse corpus of natural long-text data, such as Common Crawl, arXiv, books, and code repositories.
However, these data doesn’t clearly link things that are far apart. This happens because when we write or speak, we tend to focus on making sense locally, from one sentence to the next. Lack of proper long-range relationships in text data creates a challenge for language models to learn how things relate when they’re far apart.
To enhance the model’s ability to understand long-range dependencies, the natural corpus was augmented with synthetic data. This synthetic data included tasks such as:
- Fill in the Middle (FIM): Predicting missing segments within a text sequence, which encourages integrating distant contextual information.
- Keyword and Position-Based Retrieval: Retrieving relevant paragraphs based on keywords or positions, which improves understanding of positional relationships.
- Paragraph Reordering: Reordering shuffled paragraphs, which strengthens recognition of logical flows and structural coherence.
Training Strategy
The training process for the Qwen2.5-1M models used a progressive context length expansion strategy, divided into five stages:
- Initial Training (4,096 tokens): An intermediate version from Qwen2.5 Base models was used.
- Expansion to 32,768 tokens: Adaptive Base Frequency (ABF) was employed to adjust the base frequency of RoPE from 10,000 to 1,000,000.
- Expansion to 65,536 tokens: RoPE base frequency set to 1,000,000.
- Expansion to 131,072 tokens: RoPE base frequency set to 5,000,000.
- Expansion to 262,144 tokens: RoPE base frequency set to 10,000,000.

During the last three stages, 75% of the training data consisted of sequences at the current maximum length, and the other 25% consisted of shorter sequences. This approach helped the model adapt to longer contexts while maintaining its capability to process shorter sequences.
The performance of Qwen2.5-14B-1M on the RULER benchmark during each pre-training stage shows a significant enhancement of long sequence comprehension. Training with longer sequences consistently improved the model’s ability to process longer sequence lengths.
Post-Training
Synthesizing Long Instruction Data
- Synthetic data was generated using the pre-training corpus to address the lack of available long instruction data.
- Tasks included summarization, information retrieval, reasoning, and coding.
- The Qwen-Agent framework was used to generate high-quality responses based on the full documents. Techniques used included retrieval-augmented generation, chunk-by-chunk reading, and step-by-step reasoning.
- This process created synthetic training data composed of full documents, model-generated queries, and agent-based generated responses.
Two-Stage Supervised Fine-Tuning (SFT)
To enhance the model’s performance on long-context tasks without compromising its performance on shorter tasks, a two-stage training scheme was implemented:
- Stage 1: Training on short instruction data (up to 32,768 tokens) with the same data and steps as the 128K versions of Qwen2.5.
- Stage 2: Mixed training on short (up to 32,768 tokens) and long (up to 262,144 tokens) instructions to improve long-context task performance while maintaining short-task quality.
Reinforcement Learning (RL)
- Offline reinforcement learning (RL) similar to Direct Preference Optimization (DPO) was used to enhance alignment with human preferences.
- Models were trained on short samples (up to 8,192 tokens) from the offline RL phase of other Qwen2.5 models.
- This short sample training improved alignment with human preferences and generalized well to long-context tasks.
Inference Techniques
1. Length Extrapolation through Dual Chunk Attention (DCA)
LLMs that use RoPE get worse at handling text longer than what they were trained on. This is because they run into combinations of word positions they haven’t seen before.
During training, the models trained with context length of 256k tokens. To extend this to 1M tokens, length extrapolation techniques were employed. The core technique used here was Dual Chunk Attention (DCA).
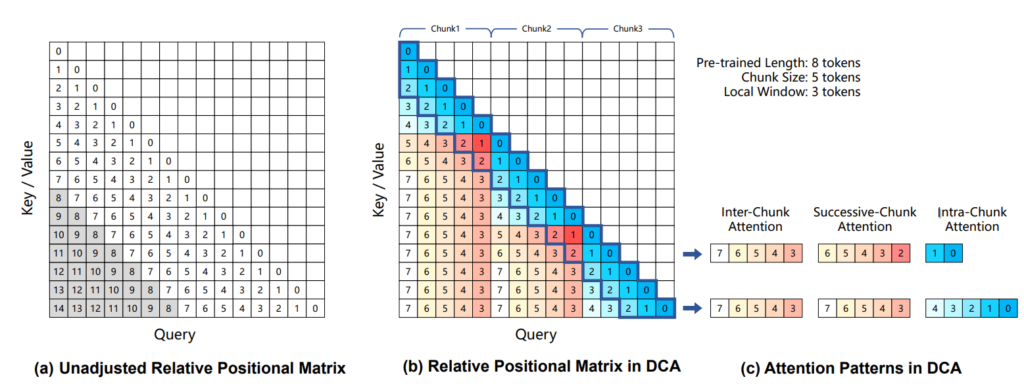
DCA is used to remap relative positions to smaller values, which avoids the large distances not seen during training. It divides the entire sequence into multiple chunks, and remapping the relative positions into smaller numbers. This ensures the distance between any two tokens does not exceed the pre-training length. DCA employs three distinct attention patterns:
- Intra-Chunk Attention: Handles attention between tokens within the same chunk, preserving the original relative positions.
- Inter-Chunk Attention: Manages attention between tokens in different chunks, using repeated sequences as relative positions.
- Successive-Chunk Attention: Manages attention between two adjacent chunks, retaining the original relative positions within a local window, and using the Inter-Chunk approach for longer distances.
2. Attention Scaling in YaRN
Attention mechanism is distracted when processing long sequences. To address this issue, a temperature parameter is introduced to the attention logits. This scaling factor helps the model focus on the key information, and is defined as:
\[
\text{softmax} \bigg(\frac{q^Tk}{t \sqrt D}\bigg), \;\;\;\; \text{where} \frac{1}{\sqrt t} = 0.1\; \text{ln}(s)+1
\]
where \(q\) and \(k\) represent query and key vectors, \(t\) is a temperature parameter, and \(D\) is the dimension of each attention head. The scaling factor \(s\) is the ratio of inference length to training length.
3. Sparse Attention
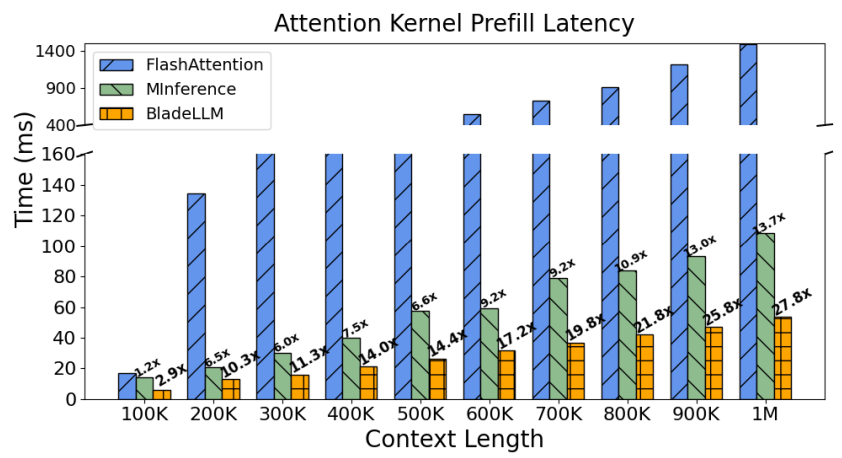
Standard attention mechanisms get significantly slower as the input text gets longer (computational complexity scales quadratically with the length of the input sequence). For 1M input tokens, calculating attention takes up almost 90% of the processing time. To improve the inference speed of long-context language models, a sparse attention mechanism was employed, using MInference as its base.
- MInference accelerates the prefill phase by only using critical tokens for attention computation. It identifies a ‘Vertical-Slash’ pattern in attention maps. MInference uses an offline search to determine the optimal sparsification configuration for each attention head, specifying the number of vertical and diagonal lines to adopt. During inference, it initially computes attention between the last query tokens and all key tokens and dynamically selects critical tokens, significantly reducing computational costs while minimizing accuracy loss.
- Sparsity Refinement: Identifying optimal sparsification in MInference requires full attention matrices, which scale quadratically with sequence length. Typically this window is kept low (32K), leading performance degradation in longer sequence. To address the issue, a method was developed to refine the sparsification configuration. This approach leveraged Flash Attention to calculate attention recall, which indicates how well the critical tokens are captured in sparse attention compared to full-attention computation.
- Integration with Chunked Prefill: Chunked prefill is used to reduce VRAM consumption, by processing sequences in chunks. MInference was modified to select critical tokens for each chunk separately, rather than for the entire sequence. This significantly increases the supported sequence length within limited VRAM resources.
- Integration with Length Extrapolation: DCA was integrated with MInference for long context processing, and also continuous relative positions were introduced when selecting critical tokens. This maintains a consistent “slash” pattern and improves accuracy.
The evaluation of Qwen2.5-7B-Instruct-1M using the Needle in a Haystack Test highlights the importance of the method of integrating DCA and sparsity refinement, showing that the approach recovers most of the performance while maintaining speedup.
4. Inference Engine
The inference engine for the Qwen2.5-1M models is powered by BladeLLM, a high-performance inference engine by Alibada Cloud. This engine has been optimized for long-sequence prefill and decoding through enhancements in kernel performance, pipeline parallelism, and scheduling algorithms.
- Sparse Attention Kernel Optimization: To enhance the efficiency of the attention kernel after sparsification, multi-stage pipeline parallelism and instruction-level optimization were implemented when loading sparse KV pairs from global memory. The optimized kernel achieves a much higher FLOPs utilization rate than FlashAttention.
- MoE Kernel Optimization: Memory access speed significantly impacts the decoding performance of Mixture-of-Experts (MoE) models. BladeLLM enhances the efficiency of MoE kernels through techniques like improved Tensor Core utilization and fine-grained warp specialization, which improves memory access efficiency.
- Dynamic Chunked Pipeline Parallelism: Dynamic Chunked Pipeline Parallelism (DCPP) dynamically adjusts chunk sizes based on the computation complexity of the attention kernel. This ensures that the execution time of each chunk is as equal as possible, which minimizes pipeline bubbles.
- Scheduling Optimization: BladeLLM uses a Totally Asynchronous Generator (TAG) architecture, which handles different components (scheduler, model runner, and decoder) in separate processes without synchronization. Shared memory is employed to further reduce inter-process communication overhead. This reduces overhead in non-GPU stages of the inference engine, substantially enhancing decoding efficiency.
Performance Evaluation
Long-Context Tasks
The Qwen2.5-1M series of models were evaluated on the Passkey Retrieval task with a 1 million token context, with models successfully retrieving hidden numbers in the extensive context. For more complex long-context tasks, the models were evaluated using three benchmarks:
- RULER: Measures the ability to find multiple “needles” or answer multiple questions within irrelevant contexts.
- LV-Eval: Tests the model’s ability to understand numerous evidence fragments simultaneously.
- Longbench-Chat: Evaluates human preference alignment in long-context tasks.

The Qwen2.5-1M series models significantly outperformed their 128k counterparts in most long-context tasks, particularly for sequences exceeding 64k in length. The Qwen2.5-14B-Instruct-1M model consistently outperformed GPT-4o-mini across multiple datasets. Qwen2.5-Turbo achieved a good balance of performance, speed, and cost-effectiveness.
Short-Context Tasks
The models were compared with the 128k versions on widely used academic benchmarks. These benchmarks target natural language understanding, coding, mathematics, and reasoning. They also include tests of instruction-following capabilities and human preference alignment.
The Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M maintained performance on short text tasks that was similar to the 128k versions, ensuring that their fundamental capabilities were not compromised by the addition of long-sequence processing abilities. The models also achieved similar performance to GPT-4o-mini on short text tasks while supporting a context length that is eight times longer.
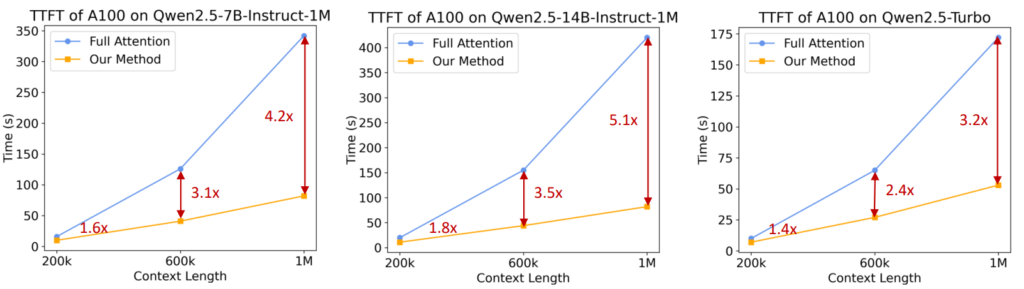
Speed Comparison
The Time to First Token (TTFT) for different context lengths was measured on Nvidia H20 and A100 GPUs, showing that the sparse attention and optimized inference engine achieved a 3.2 to 6.7 times speedup when processing a 1M token context.
The Qwen2.5-Turbo model achieved shorter processing times and lower costs compared to the open-source models while still achieving competitive results on both short and long context tasks.
Deployment
System Requirements
For optimal performance, the following is recommended:
- GPUs with Ampere or Hopper architecture that support optimized kernels.
- CUDA Version 12.1 or 12.3.
- Python Version >= 3.9 and <= 3.12.
VRAM requirements for processing 1 million token sequences:
- Qwen2.5-7B-Instruct-1M: At least 120GB VRAM (total across GPUs).
- Qwen2.5-14B-Instruct-1M: At least 320GB VRAM (total across GPUs).
If the available VRAM is not sufficient, the models can still be used for shorter tasks.
Installation
The vLLM repository needs to be cloned from a custom branch and installed manually. The branch is being merged into the main vLLM project. The following command is used:
git clone -b dev/dual-chunk-attn git@github.com:QwenLM/vllm.git
cd vllm
pip install -e . -vLaunching the API Service
The API service is started using the following command:
vllm serve Qwen/Qwen2.5-7B-Instruct-1M \
--tensor-parallel-size 4 \
--max-model-len 1010000 \
--enable-chunked-prefill --max-num-batched-tokens 131072 \
--enforce-eager \
--max-num-seqs 1 # --quantization fp8Key parameters:
- –tensor-parallel-size: The number of GPUs being used (max 4 GPUs for 7B model, 8 for 14B).
- –max-model-len: The maximum input sequence length. Can be reduced to prevent Out of Memory issues.
- –max-num-batched-tokens: Sets the chunk size in Chunked Prefill, with a recommended value of 131072 for optimal performance.
- –max-num-seqs: Limits concurrent sequences processed.
Interacting with the Model
The deployed model can be interacted with using options like curl and Python, as well as other advanced use cases.
Using Curl
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{ "model": "Qwen/Qwen2.5-7B-Instruct-1M", "messages": [ {"role": "user", "content": "Tell me something about large language models."} ], "temperature": 0.7, "top_p": 0.8, "repetition_penalty": 1.05, "max_tokens": 512 }'Using Python
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key = openai_api_key,
base_url = openai_api_base,
)
prompt = (
"There is an important info hidden inside a lot of irrelevant text. "
+ "Find it and memorize it. I will quiz you about the important information there. \n\n "
+ "The pass key is 28884. Remember it. 28884 is the pass key. \n "
+ "The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again. "
* 800
+ " \n What is the pass key?"
)
chat_response = client.chat.completions.create(
model = "Qwen/Qwen2.5-7B-Instruct-1M",
messages = [{ "role" : "user" , "content" : prompt }],
temperature = 0,
)
print( "Chat response:" , chat_response.choices.message.content )
Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!