Large Concept Models (LCMs) [paper] represent a significant evolution in NLP. Instead of focusing on individual words or subword tokens, LCMs operate on the level of “concepts,” which are typically represented by entire sentences, allowing for more sophisticated reasoning and contextual comprehension. This shift in approach offers several advantages, including improved efficiency, enhanced coherence in text generation, and unparalleled zero-shot generalization across languages.
The Need for LCMs
The development of LCMs is driven by the need to address limitations inherent in LLMs and move beyond their generative capabilities into the realm of conceptual understanding and reasoning. While LLMs have proven revolutionary in various applications, their dependence on massive datasets and token-based processing creates several drawbacks:
- Specialisation over Generalisation: LLMs, trained on vast and diverse datasets, often possess shallow domain knowledge. LCMs counter this by concentrating on domain-specific expertise, making them more reliable in fields like medicine, law, or engineering.
- Efficiency in Resource Utilization: The immense computational resources required to train and deploy LLMs pose a challenge. LCMs, being more focused, operate with reduced data and computational needs, leading to cost and energy savings.
- Conceptual Depth: LLMs, despite their linguistic fluency, often struggle with tasks demanding in-depth reasoning or understanding of complex concepts. LCMs are purpose-built to overcome this limitation by embedding conceptual frameworks directly into their architecture.
- Overfitting to Linguistic Patterns: LLMs, due to their reliance on patterns rather than true understanding, often generate plausible-sounding but factually incorrect information.
- Domain Ambiguity: LLMs lack the depth required for highly specialised tasks, frequently necessitating extensive fine-tuning and additional validation layers.
The shift from tokens to concepts is crucial because humans operate at multiple levels of abstraction, far beyond individual words. LCMs, by processing information at the concept level, aim to bridge the gap between data and knowledge, facilitating deeper insights and enhancing critical decision-making. This approach is analogous to perceiving a scene by understanding its constituent objects and relationships rather than examining individual pixels.
The Core Principles of LCMs
The core principles of LCMs centre around processing information hierarchically, mimicking how humans think and structure ideas. Here’s a breakdown of the key principles:
- Concept-Based Processing: Unlike LLMs that process individual words or subword tokens, LCMs work with larger, more meaningful units of information – sentences as “concepts.” This abstraction allows the model to operate at a higher level of understanding, similar to how humans think in ideas rather than isolated words.
- Language-Agnostic Representation: LCMs leverage embedding systems like SONAR to encode sentences into a universal semantic space supporting over 200 languages. This language-independent representation enables zero-shot generalisation across languages and eliminates the need for language-specific retraining.
- Hierarchical Information Processing: LCMs are designed to operate hierarchically, mirroring the way humans structure their thoughts. This hierarchical structure is evident in the architecture, with the initial extraction of concepts, followed by reasoning based on these concepts, and finally the generation of the output. This approach enables the model to handle long contexts more effectively and perform better hierarchical reasoning, leading to more coherent and well-structured texts.
- Modularity and Extensibility: The modular design of LCMs allows for independent development and optimisation of concept encoders and decoders without modality competition. This modularity also enables the seamless integration of new languages or modalities, such as speech and text, making the model incredibly versatile.
The Architectures of LCMs

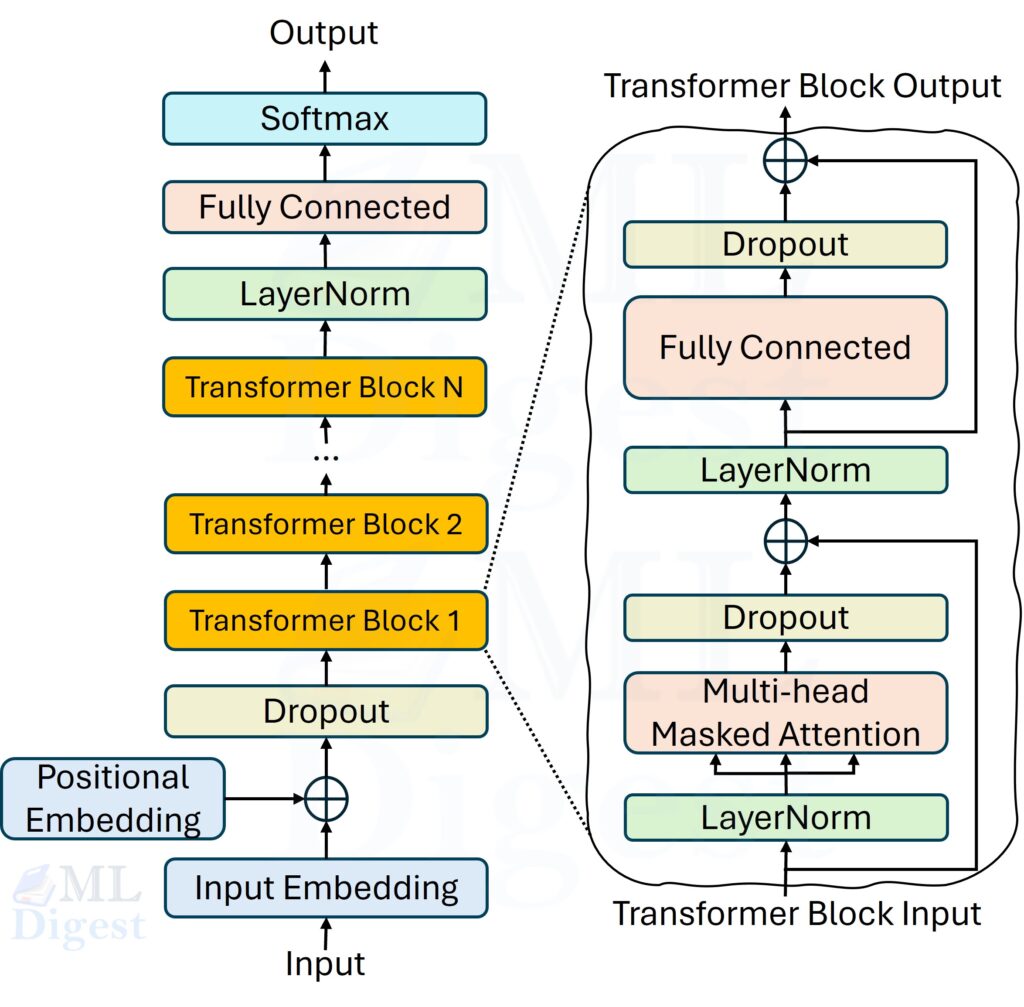
LCMs distinguish themselves from LLMs through their unique architecture designed for concept-level processing. Here’s a detailed description of the core components and operational flow:
1. Input Segmentation and Encoding:
- The input text is first segmented into sentences, each representing a distinct “concept“.
- These sentences are then passed through a concept encoder, which transforms them into concept embeddings.
- The LCM paper primarily employs SONAR, a pre-trained sentence embedding model, as the concept encoder. SONAR supports over 200 languages and multiple modalities, including speech, making the LCM inherently multilingual and multimodal. SONAR utilises character-level tokenisation before encoding sentences into embeddings.
2. Large Concept Model (LCM) Module:
- The sequence of concept embeddings is then processed by the core LCM module. This module operates exclusively in the embedding space, making it language and modality agnostic.
- The LCM’s primary function is to predict the next concept embedding, given the preceding sequence of concepts. This process is analogous to next-token prediction in LLMs but operates at a higher level of abstraction.
3. Concept Decoding:
- The concept embeddings generated by the LCM are decoded back into a language-specific format using the decoder component of SONAR.
- This decoder can produce outputs in various languages or modalities depending on the task requirements.
What are the advantages of LCM over LLM for AI tasks?
LCMs offer several advantages over traditional LLMs when handling long-context inputs. These advantages stem from LCM’s ability to process information at the sentence or “concept” level, rather than at the token level.
- Reduced Sequence Length: LCMs operate on sequences of sentences, which are significantly shorter than the corresponding sequences of tokens for the same input. This reduction in sequence length is crucial because the computational cost of traditional transformer models increases quadratically with sequence length. By working with sentences as the basic units, LCMs can manage extended contexts more efficiently.
- Hierarchical Reasoning: Processing concepts instead of subword tokens allows for better hierarchical reasoning. LCMs can outline a flow of higher-level ideas instead of processing every word, similar to how a researcher would prepare for a presentation. This approach enables the model to maintain a more coherent narrative flow and reduces informational dispersion, which can be a challenge in traditional LLMs when they construct text token by token.
- Efficient Resource Utilisation: By processing sentences as concepts, LCMs require less computational power and data. This efficiency translates into reduced costs and faster deployment cycles. LLMs, on the other hand, often demand substantial computational resources and training data.
- Improved Coherence: By operating on sentences, LCMs are better equipped to maintain coherence in long-form text. They can generate well-structured and logically connected outputs, which is essential for tasks like summarisation, content expansion, and narrative generation.
- Scalability: LCMs can be easily updated and scaled within specific domains without retraining the entire model, due to their modular design. This scalability is particularly beneficial for applications that require continuous learning or adaptation to new information.
- Multilingual Capabilities: LCMs, particularly those based on the SONAR embedding space, can leverage a single semantic space that represents sentences across many languages, allowing them to process inputs and generate outputs in different languages without needing to readjust their reasoning process. This is a significant advantage over LLMs, which often require additional data to cover more languages.
- Explicit Planning: LCMs can also be conditioned on a plan, which is a higher-level overview of the content, which is useful for generating long-form outputs. This capability allows LCMs to predict a structural scheme that they can follow to ensure greater narrative coherence.
- Enhanced Zero-Shot Generalisation: LCMs exhibit better zero-shot generalisation, which is the ability to perform tasks in languages or modalities not included in their initial training. This is due to their language-agnostic approach and ability to operate in a semantic space. LLMs can struggle with overfitting to linguistic patterns.
LCM Variants
Researchers have explored various architectures for the LCM module to optimize its performance:
- Base-LCM: This basic architecture utilizes a standard transformer decoder to predict the next concept embedding, employing Mean Squared Error (MSE) as the loss function. However, this method can lead to “semantic averaging”, where the model predicts an average representation instead of capturing the multifaceted nature of sentence-level meaning.
- Diffusion-Based LCM: Drawing inspiration from diffusion models used in image generation, this approach iteratively refines concept embeddings from a noisy starting point to a final prediction. There are two main variants:
- One-Tower LCM: A single transformer handles both context encoding and concept denoising.
- Two-Tower LCM: The architecture separates context encoding and denoising processes, using a dedicated “contextualizer” and “denoiser”. This modularity allows for more specialised processing and potentially better performance.
- Quantized LCM: This approach seeks to discretise the continuous concept embeddings, employing techniques like Residual Vector Quantization (RVQ). This method aims to address the inherent discreteness of language while operating in the concept space.
Evaluation of LCMs
Metrics: Evaluating LCMs, particularly for generative tasks, involves various metrics that capture different aspects of model performance:
- Embedding-Level Metrics:
- L2 distance (\(l_2\)): Measures the Euclidean distance between the predicted concept embedding and the ground truth embedding.
- Round-trip L2 distance (\(l_{2-r}\)): Accounts for potential shifts in the embedding space after decoding and re-encoding, highlighting the model’s ability to generate plausible embeddings.
- Paraphrasing (PAR): Assesses the similarity between predicted and ground truth embeddings using cosine similarity.
- Contrastive Accuracy (CA): Evaluates how well the model distinguishes between correct and incorrect continuations.
- Mutual Information (MI): Measures the amount of information shared between the predicted concept and the preceding context, indicating the model’s ability to generate coherent continuations.
- Text-Level Metrics:
- ROUGE-L: A standard metric for evaluating summarisation quality by measuring the longest common subsequence between generated and reference texts.
- Coherence: Assesses the logical consistency and flow of generated text, often using a pre-trained coherence classifier or human judgements.
- Fluency: Measures the grammatical correctness and naturalness of the generated text, typically using metrics like perplexity or the CoLA classifier.
- Word Overlap Metrics: Quantify the extent to which the model copies content from the source (OVL-3) or repeats its own generations (REP-4).
- Seahorse Metrics (SH-4, SH-5): Employ specialised classifiers to evaluate the source attribution and semantic coverage of summaries.
Datasets: Evaluation is conducted on various datasets, including standard summarization benchmarks like CNN DailyMail and XSum, as well as datasets specifically designed for long-form generation or challenging tasks like summary expansion.
Results
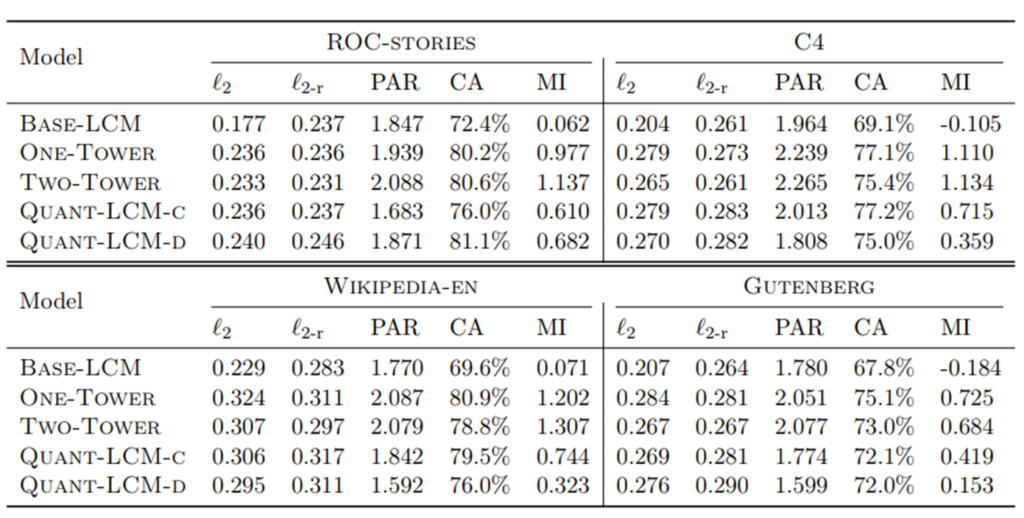
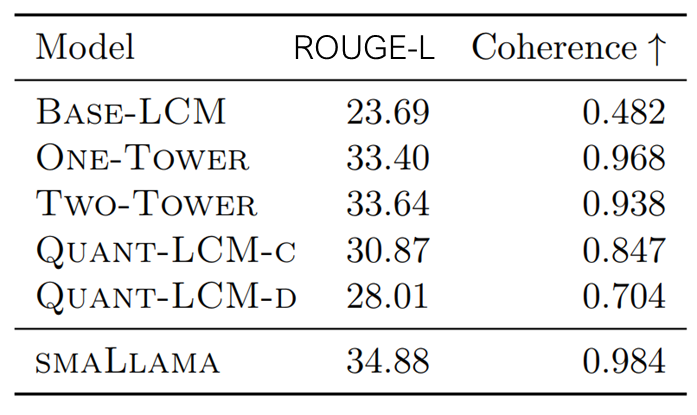
Advantages of LCMs
The research highlights several advantages of LCMs over traditional LLMs:
- Better long context handling: By processing sequences of concepts instead of individual tokens, LCMs can significantly reduce the sequence length, simplifying the management of extended contexts. This advantage is particularly beneficial for tasks like summarization or reasoning over large texts.
- Hierarchical reasoning: Operating on concepts rather than tokens enables LCMs to perform better hierarchical reasoning, mimicking the human process of outlining high-level ideas and then adding details. This hierarchical approach can lead to more coherent and well-structured texts.
- Zero-shot generalisation: LCMs demonstrate impressive zero-shot generalisation capabilities, extending to languages not included in the initial training process. This advantage stems from their operation in a language-agnostic embedding space, allowing them to leverage the multilingual nature of encoders like SONAR.
- Enhanced efficiency and scalability: Processing concepts instead of tokens significantly improves efficiency and reduces computational costs. This advantage makes LCMs particularly attractive for organisations with limited resources.
- Improved Coherence in Long-Form Text Generation: LCMs’ hierarchical approach, mimicking human thought processes, allows for the creation of more coherent and well-structured outputs. They excel in tasks like summarisation, content expansion, and multilingual communication.
- Multilingual Capabilities: LCMs, leveraging embedding systems like SONAR, can handle a wide array of languages, making AI tools more inclusive and accessible for global communities.
Applications of LCMs
LCMs hold immense potential across various domains, including:
- Healthcare: Assisting medical professionals with diagnoses, treatment recommendations, and drug discovery.
- Legal: Interpreting laws and precedents for case analysis and legal strategy.
- Education: Personalising learning systems and optimising teaching materials.
- Engineering: Streamlining complex system design by integrating technical specifications and industry standards.
- Finance: Providing insights for investment, risk management, and financial planning.
- Policy Development: Crafting evidence-based policies by analysing historical data and modelling potential outcomes.
Conclusion
LCMs represent a paradigm shift in AI, moving beyond the limitations of purely token-based LLMs and embracing a more conceptually driven approach to language processing. Their ability to handle long contexts, reason hierarchically, and generalise across languages opens up exciting possibilities for developing more efficient, coherent, and impactful AI applications in the future.
Resources:

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!