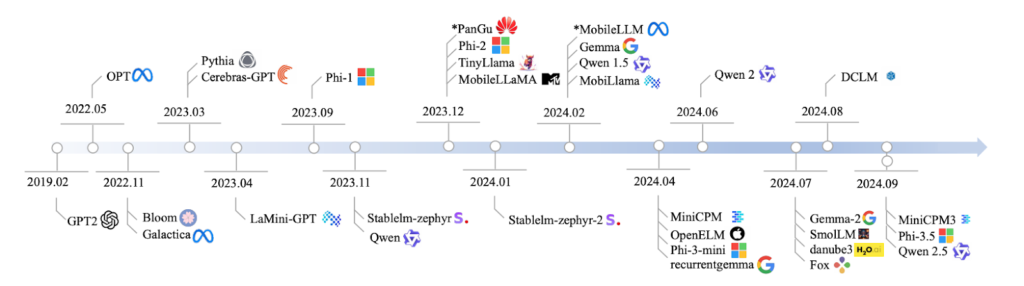
Qwen2.5 marks a significant milestone in the evolution of open-source language models, building upon the foundation established by its predecessor, Qwen2. It’s one of the largest open-source releases ever, offering a range of models for different tasks like coding, math, and general language understanding. These models outperform previous versions on various benchmarks.
Key Features of Qwen2.5
- Model Variants:
- Qwen2.5: Available in sizes of 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B.
- Qwen2.5-Coder: Specialized for coding tasks with sizes of 1.5B, 7B, and a 32B version forthcoming.
- Qwen2.5-Math: Focused on mathematical tasks available in sizes of 1.5B, 7B, and 72B.
- Licensing: All models except for the 3B and 72B variants are licensed under Apache 2.0.
- APIs: Access to flagship models like Qwen-Plus and Qwen-Turbo through Model Studio.
Performance Enhancements
Qwen2.5 has been pretrained on a substantial dataset containing up to 18 trillion tokens, leading to significant improvements over its predecessor:
- Knowledge Acquisition: MMLU score improved to 85+.
- Coding Capabilities: Achieved a HumanEval score of 85+.
- Mathematical Proficiency: MATH score reached 80+.
Additional enhancements include:
- Improved instruction following and long text generation (over 8K tokens).
- Better understanding and generation of structured data (e.g., JSON).
- Enhanced multilingual support for over 29 languages, including major languages like English, Chinese, Spanish, and Arabic.
Specialized Models
Qwen2.5-Coder
Designed for coding applications, Qwen2.5-Coder has shown remarkable performance:
- Trained on 5.5 trillion tokens of code-related data.
- Outperforms many larger models in various programming tasks despite its smaller size.
Qwen2.5-Math
The math-focused model has also seen significant improvements:
- Pretrained on a larger scale of math-related data.
- Supports both Chinese and English with enhanced reasoning capabilities through methods like Chain-of-Thought (CoT), Program-of-Thought (PoT), and Tool-Integrated Reasoning (TIR).
Benchmarking Performance
The Qwen2.5-72B model has been benchmarked against leading open-source models such as Llama-3.1-70B and Mistral-Large-V2, showcasing its competitive edge in instruction-following tasks and general language understanding. Notably, it also competes effectively against larger proprietary models like GPT-4.
- The largest model, Qwen2.5-72B, demonstrates top-tier performance even against larger models like Llama-3-405B.
- Smaller Qwen2.5 models (14B and 32B) also demonstrate strong performance, outperforming comparable or larger models like Phi-3.5-MoE-Instruct and Gemma2-27B-IT.
- The API-based model Qwen-Plus competes well against proprietary models like GPT4-o and Claude-3.5-Sonnet.
Key Concepts
- Qwen models are causal language models, also known as autoregressive or decoder-only language models.
- It uses a byte-level Byte Pair Encoding (BPE) tokenization method.
- Qwen has a large vocabulary of 151,643 tokens, allowing it to handle the diversity of human language (supports over 29 languages).
- It uses the ChatML format, which employs control tokens to define each turn in a conversation. <|im_start|>{{role}} {{content}}<|im_end|>
Development with Qwen2.5
Developers can easily use Qwen2.5 through Hugging Face Transformers with the following code snippet:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(model_inputs, max_new_tokens=512)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]Additionally, Qwen2.5 supports deployment via vLLM or Ollama for API compatibility.
Community Contributions
The development of Qwen is supported by numerous collaborators across various domains:
- Finetuning: Peft, ChatLearn
- Quantization: AutoGPTQ
- Deployment: vLLM, TensorRT-LLM
- API Platforms: Together, OpenRouter
- Evaluation: LMSys, OpenCompass
Future Directions
The team acknowledges ongoing challenges in developing robust foundation models across various domains (language, vision-language, audio-language). Future goals include:
- Integrating different modalities into a single model for seamless processing.
- Enhancing reasoning capabilities through advanced data scaling techniques.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!