DeepSeek-R1 represents a significant advancement in the field of LLMs, particularly in enhancing reasoning capabilities through reinforcement learning (RL). This model, developed by DeepSeek-AI, distinguishes itself through its unique training pipeline and its capacity to achieve performance comparable to OpenAI’s o1-1217 on various reasoning tasks. The research focuses on exploring the potential of LLMs to develop strong reasoning abilities without relying on extensive supervised fine-tuning (SFT) data, instead using a pure RL approach.
Background
The OpenAI o1 series models were the first to introduce inference-time scaling by increasing the length of the Chain-of-Thought (CoT) reasoning process, significantly improving performance on tasks like mathematics, coding, and scientific reasoning. However, the challenge of effective test-time scaling remains a significant research area.
The DeepSeek-R1 project aims to address this gap by improving LLM’s reasoning capabilities using pure RL. It investigates the ability of LLMs to develop reasoning capabilities without any supervised data, focusing on their self-evolution through a pure RL process.
Key Contributions
The core contributions of the DeepSeek-R1 project are threefold:
- Large-Scale Reinforcement Learning: RL is directly applied to the base model without relying on SFT as a preliminary step. This approach allows the model to explore CoT for solving complex problems, resulting in the development of DeepSeek-R1-Zero. This model demonstrates capabilities such as self-verification, reflection, and generating long CoTs purely through RL.
- Pipeline for DeepSeek-R1: It introduces a pipeline to develop DeepSeek-R1 that incorporates two RL stages to discover improved reasoning patterns and align with human preferences, as well as two SFT stages that serve as the seed for the model’s reasoning and non-reasoning capabilities.
- Distillation: It demonstrates that reasoning patterns of larger models can be distilled into smaller models, resulting in better performance compared to the reasoning patterns discovered through RL on small models.
DeepSeek-R1-Zero: Reinforcement Learning on the Base Model
- DeepSeek-R1-Zero is a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step.
- It was developed to explore the potential of LLMs to develop reasoning capabilities without any supervised data, emphasizing self-evolution through a pure RL process.
Training Process:
- The base model for both DeepSeek-R1-Zero and DeepSeek-R1 is DeepSeek-V3-Base.
- Group Relative Policy Optimization (GRPO) is used to perform RL. GRPO does not use the critic model, rather estimates the baseline from group scores. For each question \(q\), GRPO samples a group of outputs \( \{o1, o2, …, oG\} \) from the old policy to set the baseline and then optimizes the policy by generating next group of outputs t maximize advantage.
- Reward Modelling: The reward system is essential for guiding the optimization direction of RL. The reward system for DeepSeek-R1-Zero consists of two types of rewards:
- Accuracy Rewards (rule-based): These rewards evaluate whether the response is correct. For math problems, the model must provide the final answer in a specific format, enabling rule-based verification of correctness. For LeetCode problems, a compiler generates feedback based on test cases.
- Format Rewards: This model enforces the model to put its thinking process between
<think>and</think>tags.
- Training Template: The training template guides the base model to adhere to specified instructions. The template requires the model to first produce a reasoning process, followed by the final answer.
Performance of DeepSeek-R1-Zero:
- DeepSeek-R1-Zero demonstrates a steady and consistent enhancement in performance as the RL training advances.
- The average pass@1 score on AIME 2024 significantly increases from 15.6% to 71.0%, reaching performance levels comparable to OpenAI-o1-0912.
- The performance of DeepSeek-R1-Zero can be enhanced through majority voting; for example, on the AIME benchmark, the model’s performance increases from 71.0% to 86.7%, surpassing the performance of OpenAI-o1-0912.

The model learns to allocate more thinking time to a problem by reevaluating its initial approach (as shown in above image). This underscores the power of RL to allow the model to autonomously develop advanced problem-solving strategies. This highlights the potential of RL to unlock new levels of intelligence in artificial systems.
Drawbacks of DeepSeek-R1-Zero:
DeepSeek-R1-Zero faces several challenges such as (1) poor readability, and (2) language mixing. To make reasoning processes more readable, DeepSeek-R1 was developed utilizing RL with human-friendly cold-start data.
DeepSeek-R1: Reinforcement Learning with Cold Start
DeepSeek-R1 builds upon the foundations laid by DeepSeek-R1-Zero by incorporating a small amount of high-quality data as a cold start to improve reasoning performance and create a user-friendly model. The pipeline consists of two reinforcement learning (RL) stages and two supervised fine-tuning (SFT) stages:
- Cold Start Fine-tuning
- Reasoning-oriented Reinforcement Learning
- Rejection Sampling and Supervised Fine-Tuning
- Reinforcement Learning for all Scenarios
Cold Start Fine-tuning (1st SFT Stage)
- DeepSeek-R1 uses a small amount of long CoT data to fine-tune the DeepSeek-V3-Base as the starting point for RL.
- Collection Methods: This data was collected by
- using few-shot prompting with long CoT examples,
- directly prompting models to generate detailed answers with reflection and verification,
- gathering DeepSeek-R1-Zero outputs in a readable format, and
- refining the results through post-processing by human annotators.
- Format and Content: The cold-start data was designed to be human-readable and followed a specific pattern:
|special_token|<reasoning_process>|special_token|<summary>. This included the CoT for the query (the reasoning process) and a summary of the reasoning results, ensuring the responses were clear and easy to understand. Responses that mixed languages or lacked user-friendly formatting were filtered out. - The advantages of cold start data compared to DeepSeek-R1-Zero include:
- Improved Readability: The content of DeepSeek-R1-Zero is often not suitable for reading with mixed languages or a lack of markdown formatting to highlight answers for users. The cold-start data was specifically designed to address these issues by enforcing a readable format with clear summaries and language consistency.
- Better Performance: With a careful design for the cold-start data with human priors, the researchers have observed better performance.
- Stable Start: Using cold-start data aimed to avoid the unstable early phases of RL training.
- The purpose of this stage was to provide a stable and human-friendly starting point for the subsequent RL process, overcoming the unstable start of RL directly on the base model as seen in DeepSeek-R1-Zero.
Reasoning-oriented Reinforcement Learning (1st RL Stage)
- After fine-tuning on cold start data, large-scale RL is applied (same training process as in DeepSeek-R1-Zero).
- This stage improves the model’s reasoning capabilities, particularly in coding, mathematics, etc.
- Language consistency reward is introduced during RL training to mitigate language mixing. This is calculated as the proportion of target language words in the CoT. Although the performance is degraded slightly, this reward aligns with human preferences (more readable).
- RL training is conducted by combining the accuracy of reasoning tasks and the reward for language consistency.
- This stage used the GRPO algorithm, similar to DeepSeek-R1-Zero.
Rejection Sampling and Supervised Fine-Tuning (2nd SFT Stage)
- This stage includes SFT data from other domains to enhance the model’s capabilities in writing, role-playing, and other general-purpose tasks.
- This SFT data is collected by curating the generated reasoning trajectories from the checkpoint of the previous RL training.
- Reasoning data (600k) is curated by
- rejection sampling of reasoning trajectories (retaining correct responses only),
- incorporating additional data that uses a generative reward model (for non-rule based reward, through LLM judgement),
- filtering out nuanced reasoning trajectories with mixed languages, long paragraphs, and code blocks
- Non-reasoning data (200k), such as writing, factual QA, self-cognition, and translation, is taken from the DeepSeek-V3 pipeline and reuses portions of the SFT dataset of DeepSeek-V3.
- DeepSeek-V3-Base is fine-tuned for two epochs using the curated dataset of about 800k samples.
Reinforcement Learning for all Scenarios (2nd RL Stage)
- A secondary RL stage is implemented to improve model’s helpfulness, harmlessness, and refine reasoning capabilities.
- The model is trained using a combination of reward signals and diverse prompt distributions.
- Reasoning data is trained using the rule-based reward methodology (as in 1st and 2nd SFT stage), while general data is trained using reward models to capture human preferences (as in 2nd SFT stage).
- The helpfulness reward focuses on the final summary, while the harmlessness reward evaluates the entire response of the model, to identify and mitigate any potential risks, biases, or harmful content.
Overall Benefits of the Multi-Stage Approach
- Enhanced Reasoning Capabilities: The iterative RL stages, coupled with the focused SFT stages, allowed DeepSeek-R1 to achieve significant performance boost.
- Improved Readability and Coherence: The introduction of cold-start data and the language consistency reward specifically addressed the readability and language mixing issues observed in DeepSeek-R1-Zero, making the model’s responses more user-friendly.
- Greater Versatility: The second SFT stage, incorporating data from diverse domains, expanded DeepSeek-R1’s capabilities beyond reasoning and made it a more versatile general-purpose language model.
- Alignment with Human Preferences: The final RL stage further refined the model to be helpful and harmless, improving its suitability for general use.
DeepSeek-R1’s multi-stage training approach combined targeted fine-tuning with iterative reinforcement learning to produce a model that was not only better at reasoning, but also more readable, versatile, and aligned with human values compared to DeepSeek-R1-Zero. Each stage of the pipeline played a critical role, leading to the improved overall performance of DeepSeek-R1.
Distillation: Empowering Small Models with Reasoning Capability
- Qwen and Llama were fine-tuned using the 800k samples curated with DeepSeek-R1. (Models: Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen2.5-14B, Qwen2.5-32B, Llama-3.1-8B, and Llama-3.3-70B-Instruct)
- This direct distillation method significantly enhances the reasoning abilities of smaller models.
- For distilled models, only SFT is applied, without the RL stage, in order to demonstrate the effectiveness of the distillation technique.
DeepSeek-R1 Evaluation

- DeepSeek-R1 demonstrates superior performance compared to DeepSeek-V3 on knowledge benchmarks such as MMLU, MMLU-Pro, and GPQA Diamond due to enhanced accuracy in STEM-related questions.
- It also performs well on FRAMES, a long-context-dependent QA task, and outperforms DeepSeek-V3 on the factual benchmark SimpleQA.
- DeepSeek-R1 also delivers impressive results on IF-Eval and demonstrates strong performance on AlpacaEval2.0 and ArenaHard.
- On math tasks, DeepSeek-R1 performs on par with OpenAI-o1-1217, surpassing other models.
- A similar trend is observed on coding algorithm tasks, such as LiveCodeBench and Codeforces.
Distilled Model Evaluation:
- The distilled models, such as DeepSeek-R1-7B, outperform non-reasoning models like GPT-4o-0513.
- DeepSeek-R1-14B surpasses QwQ-32B-Preview on all evaluation metrics, while DeepSeek-R1-32B and DeepSeek-R1-70B significantly exceed o1-mini on most benchmarks.
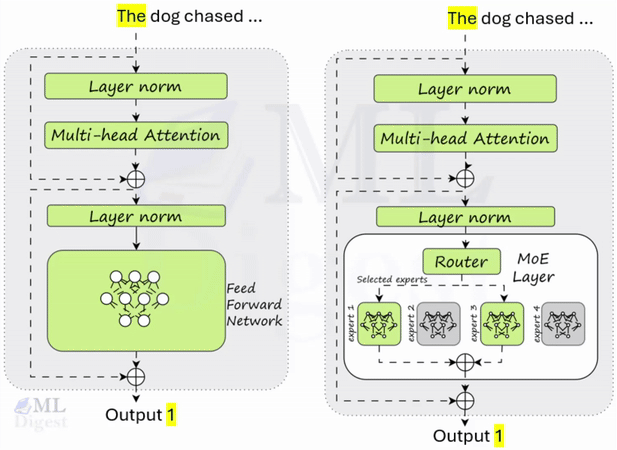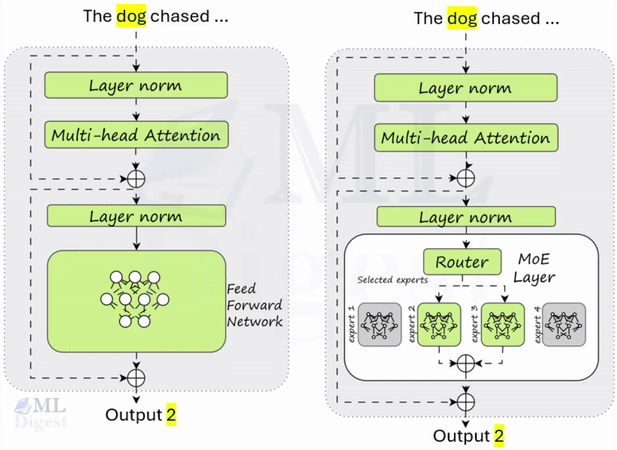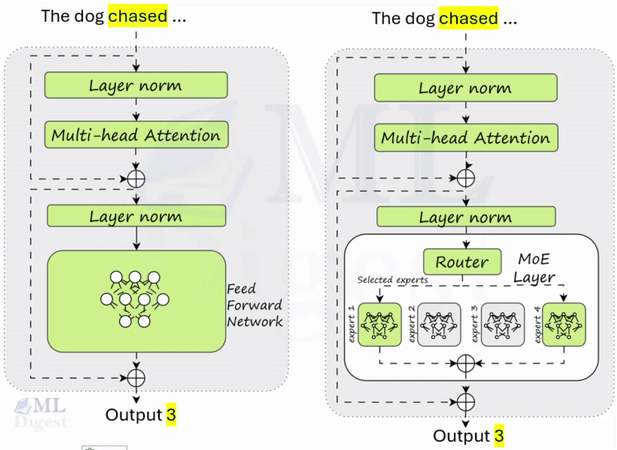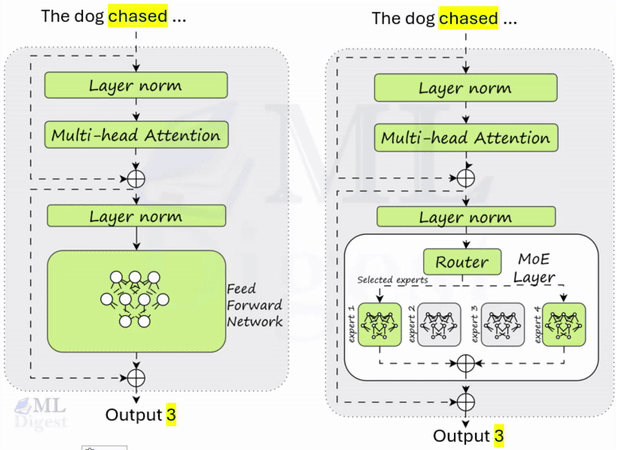
Group Relative Policy Optimization (GRPO) is a reinforcement learning algorithm adopted by DeepSeek-R1-Zero to save on training costs. The key saving comes from how it estimates the baseline for calculating the advantage, which is a critical component of the RL process.
Here’s how GRPO achieves this cost reduction:
- Traditional RL and Critic Models: Traditional RL methods often use a separate critic model, which is typically the same size as the policy model. This critic model is used to estimate the value of different actions or states, and provides the baseline for calculating the advantage. Training an additional model of this size significantly increases computational costs.
- GRPO’s Approach: Group Scores for Baseline: Instead of relying on a critic model, GRPO estimates the baseline directly from a group of scores. For each question, GRPO samples a group of outputs from the old policy. The advantage is then calculated by comparing the reward of each output to the mean reward of the group. Specifically, the advantage, A, is calculated as A = r – mean({r1, r2, …, rG}) / std({r1, r2, …, rG}) where r is the reward of the current output and r1 to rG are the rewards of the group of outputs.
- Eliminating the Need for a Critic: By estimating the baseline from group scores, GRPO foregoes the need for a separate critic model. This is the primary way it reduces computational costs. The baseline is directly calculated from the sampled outputs, removing the need for a large, additional model.
In summary, GRPO saves on training costs in RL by eliminating the need for a separate critic model. This is achieved by estimating the baseline using group scores from the current policy, which is computationally cheaper than training a separate critic model. This makes the RL process more efficient, especially in the context of large language model training, as the sizes of these models can significantly increase the computational burden when training additional critic models of similar size.
- Poor Readability: DeepSeek-R1-Zero’s responses were often not suitable for reading. The content it generated could be difficult to understand.
- Language Mixing: The model frequently mixed multiple languages within its responses. This mixing of languages made it harder to follow the reasoning process.
- Lack of Formatting: DeepSeek-R1-Zero’s responses often lacked markdown formatting to highlight answers for users. The absence of clear formatting made it difficult for users to quickly identify the final answers and summaries.
These limitations were primarily addressed in the development of DeepSeek-R1. To overcome these challenges, DeepSeek-R1 incorporated a small amount of cold-start data and a multi-stage training pipeline. The cold-start data was specifically designed to be human-readable, with a clear structure that included a summary at the end of each response. This data was used to fine-tune the base model before reinforcement learning, addressing the readability issues. Additionally, DeepSeek-R1 also introduced a language consistency reward during RL training, which encouraged the model to stick to a single language, mitigating the language mixing problem. By focusing on these improvements, DeepSeek-R1 aimed to produce more coherent and readable outputs compared to DeepSeek-R1-Zero.
DeepSeek-R1 significantly improves upon DeepSeek-R1-Zero by addressing its limitations in readability, language mixing, and overall coherence, while also enhancing its reasoning performance through a more refined training pipeline. Here’s a breakdown of the key improvements:
- Cold-Start Data: Unlike DeepSeek-R1-Zero, which starts with a base model and applies reinforcement learning (RL) directly, DeepSeek-R1 incorporates a small amount of high-quality “cold-start” data before RL. This data is used to fine-tune the base model, providing a more stable and human-friendly starting point for the RL process. This initial fine-tuning helps to establish a more readable output format and improve the model’s adherence to instructions.
- Multi-Stage Training Pipeline: DeepSeek-R1 employs a multi-stage training pipeline, which includes two RL stages and two supervised fine-tuning (SFT) stages. The first RL stage, similar to DeepSeek-R1-Zero, focuses on reasoning-oriented tasks and uses Group Relative Policy Optimization (GRPO). Following this, rejection sampling is used to create new SFT data incorporating both reasoning and non-reasoning data. A second RL stage then further refines the model taking into account prompts from all scenarios. This iterative approach allows DeepSeek-R1 to improve both its reasoning abilities and its ability to handle diverse tasks, enhancing its overall capabilities and its ability to align with human preferences.
- Improved Readability: DeepSeek-R1 addresses the readability issues of DeepSeek-R1-Zero through the use of human-generated “cold-start” data. The responses in this data include a summary at the end of each response, follow a specific, human-friendly format, and avoid language mixing. The output format is specifically designed as
|special_token|<reasoning_process>|special_token|<summary>to be more readable. This focus on human-friendly outputs makes the model’s reasoning process more transparent and easier to understand. - Reduced Language Mixing: To mitigate the language mixing issues observed in DeepSeek-R1-Zero, DeepSeek-R1 incorporates a language consistency reward during the first RL training phase. This reward encourages the model to use a consistent target language within its Chain-of-Thought reasoning process, resulting in more coherent and readable responses, and although it causes a slight degradation in performance, the improvement in readability is desirable.
- Enhanced General Capabilities: The second SFT stage incorporates non-reasoning data, from domains such as writing and factual QA, which extends the model’s general capabilities beyond reasoning. This allows DeepSeek-R1 to excel in a variety of tasks, including creative writing, general question answering, editing, and summarization, improving its usefulness as a general-purpose language model.
- Alignment with Human Preferences: The second RL stage further aligns the model with human preferences by training for helpfulness and harmlessness in all scenarios.
During the development of DeepSeek-R1, two alternative methods were explored but ultimately deemed unsuccessful due to various limitations:
Process Reward Model (PRM)
- Concept: PRM was considered as a way to guide the model towards better approaches for solving reasoning tasks by evaluating the intermediate steps in its reasoning process.
- Limitations:
- Difficulty in Defining Fine-Grained Steps: It proved challenging to explicitly define a fine-grained step in general reasoning. Unlike specific tasks where steps are clear, general reasoning can be complex and varied, making it hard to create a universal set of evaluation criteria for each step.
- Challenges in Determining Step Correctness: Assessing whether an intermediate step is correct is a difficult task. Automated annotation using models did not provide satisfactory results, and manual annotation is not scalable for large-scale reinforcement learning.
- Reward Hacking: Introducing a model-based PRM inevitably led to reward hacking, where the model exploits the reward system without genuinely improving its reasoning skills. Retraining the reward model also requires additional resources and complicates the training pipeline.
- Computational Overhead: Although PRM demonstrated an ability to re-rank the top-N responses generated by the model, or assist in guided search, its advantages were limited compared to the additional computational overhead it introduced, particularly during large-scale reinforcement learning.
- Conclusion: While PRM could be useful for reranking responses or assisting in guided searches, its limitations in terms of fine-grained step definitions, assessing correctness, reward hacking, and computational overhead made it less effective than the chosen approach for the large-scale reinforcement learning process of DeepSeek-R1.
Monte Carlo Tree Search (MCTS)
- Concept: Inspired by AlphaGo and AlphaZero, MCTS was explored to enhance test-time compute scalability. This approach involves breaking down answers into smaller parts, enabling the model to systematically explore the solution space.
- Implementation: The model was prompted to generate tags corresponding to specific reasoning steps necessary for the search. The process involved using collected prompts to find answers via MCTS, guided by a pre-trained value model, and iteratively refining the actor and value models with the resulting question-answer pairs.
- Limitations:
- Exponentially Larger Search Space: Unlike chess, where the search space is well-defined, token generation presents an exponentially larger search space. Setting a maximum extension limit for each node to address this led the model to get stuck in local optima.
- Difficulty Training Value Models: The value model directly influences the quality of generation, as it guides each step of the search process. Training a fine-grained value model proved inherently difficult, making it challenging for the model to iteratively improve. The success of AlphaGo relied on iteratively training a value model to enhance its performance. This proved difficult to replicate in their setup due to the complexities of token generation.
- Challenges in Iterative Self-Search: While MCTS can improve performance during inference when paired with a pre-trained value model, iteratively boosting model performance through self-search remained a challenge.
- Conclusion: Although MCTS can enhance performance during inference with a pre-trained value model, its inability to iteratively improve model performance through self-search, coupled with the difficulties in training value models and handling the exponential search space of token generation, made it unsuitable for the training process of DeepSeek-R1.
Concluding Remarks
DeepSeek-R1 represents a successful effort in enhancing model reasoning abilities through RL. DeepSeek-R1-Zero highlights the potential of pure RL without the need for cold-start data, while DeepSeek-R1 improves on this by leveraging cold-start data alongside iterative RL fine-tuning. Distilling reasoning capabilities to smaller dense models is also highly effective, with DeepSeek-R1-Distill-Qwen-1.5B outperforming GPT-4o and Claude-3.5-Sonnet on math benchmarks.
Reference

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!