DeepSeek V3.2 is one of the open-weight models that consistently competes with frontier proprietary systems (for example, GPT‑5‑class and Gemini 3.0 Pro as of Dec 2025) while still being deployable outside big labs. It is not a completely new architecture but a carefully engineered evolution of the DeepSeek V3 family, with three major themes:
- Efficiency at scale: long context and sparse attention on top of an already memory‑efficient backbone.
- Stronger reasoning: refined reinforcement learning with verifiable rewards, plus techniques imported from DeepSeekMath V2.
- Agentic workflows: training and evaluation centered around tool‑use and multi‑step tasks, not just standalone question‑answering.
In this article, we will first place V3.2 in the broader DeepSeek timeline, then dive into its architecture, training recipe, and finally what this means for real‑world use.
1. Where V3.2 Fits in the DeepSeek Lineup
If you picture the DeepSeek series as a research program, V3.2 is the point where several prior lines of work intersect: MoE + MLA from V2/V3, RLVR from R1, sparse attention from V3.2‑Exp, and self‑verification from DeepSeekMath V2.

From a timeline perspective:
- DeepSeek V3 (Dec 2024): base model using a Mixture‑of‑Experts (MoE) backbone. It introduced Multi‑Head Latent Attention (MLA) for more memory‑efficient attention and KV caching.
- DeepSeek R1: same architecture as V3, but trained with Reinforcement Learning with Verifiable Rewards (RLVR) to create a dedicated reasoning model. It used the GRPO algorithm (Group Relative Policy Optimization) with verifiable rewards for math and code.
- DeepSeek R1‑0528: a later training‑recipe upgrade of R1 that pushed reasoning performance closer to OpenAI o3 and Gemini 2.5 Pro without architectural changes.
- DeepSeek V3.1 and V3.1‑Terminus: hybrid reasoning models where a single model handles both instruct and reasoning tasks via prompt templates. V3.1‑Terminus is a refined checkpoint that becomes the starting point for later variants.
- DeepSeek V3.2‑Exp (Sep 2025): first introduction of DeepSeek Sparse Attention (DSA). This experimental long‑context variant adds DSA on top of V3.1‑Terminus to prepare infrastructure and tooling for sparse attention at scale.
- DeepSeekMath V2 (Nov 2025): math‑specialist model based on V3.2‑Exp‑Base that introduced self‑verification and self‑refinement for proofs.
DeepSeek V3.2 (Dec 2025) essentially combines three threads:
- The architecture of V3.2‑Exp (MoE + MLA + DSA).
- The RLVR and GRPO lineage from V3 → R1 → R1‑0528.
- The self‑verification and self‑refinement ideas validated in DeepSeekMath V2.
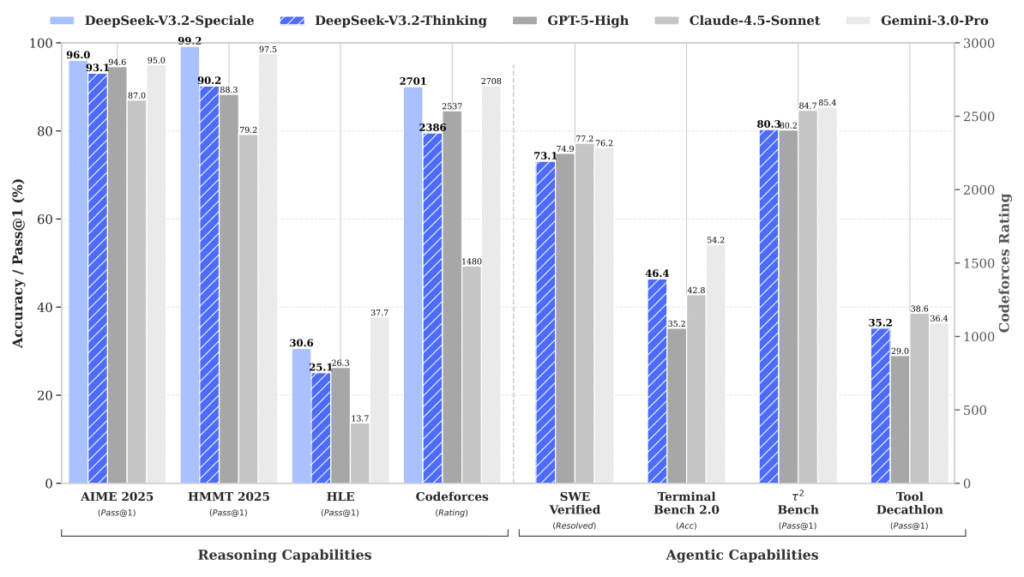
 (Benchmark of DeepSeek-V3.2 (Paper))
(Benchmark of DeepSeek-V3.2 (Paper))2. Architectural Foundations: MoE and MLA
DeepSeek V3.2 does not radically change the transformer blueprint. Instead, it layers two key efficiency mechanisms: Mixture-of-Experts for compute and Multi-Head Latent Attention for memory.
2.1 Mixture-of-Experts (MoE) Backbone
At a high level, MoE turns each transformer layer into a “committee” of expert feed‑forward networks, with a learned router deciding which experts to use for each token.
- Motivation: increase model capacity (more parameters) without linearly increasing compute per token.
- Mechanism:
- A routing network computes a probability distribution over experts for each token.
- Only the top experts (for example, 2 out of many) are activated and applied.
This makes larger‑than‑dense capacity feasible. V3.2 leverages this extra capacity for stronger reasoning and tool‑use performance without making inference prohibitively expensive.
2.2 Multi-Head Latent Attention (MLA)
Standard multi-head attention is memory-hungry because it stores full-dimensional keys and values for all tokens in the KV cache. As the context grows, this cache explodes in size. MLA addresses this by storing keys and values in a lower-dimensional latent space and only projecting them back to the full dimension when they are needed for attention.
Mechanism.
- Down‑projection: keys and values are projected into a lower‑dimensional latent space before being cached.
- Up‑projection: when attending at inference time, these compressed tensors are projected back to the original dimension.
This is similar in spirit to learned low‑rank projections (as in LoRA) but applied to the KV tensors themselves. The benefits are:
- Lower KV‑cache memory: compressed representations mean more tokens fit into GPU memory.
- Good fit for long contexts: the cost of the extra projection is outweighed by reduced memory traffic.
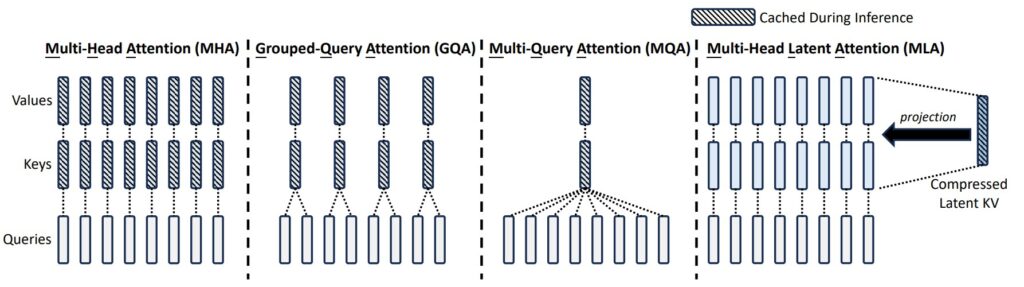
In V3.2, MLA is a core reason why long-context inference is practical, as it drastically reduces the GPU memory required to store the history of the conversation.
3. DeepSeek Sparse Attention (DSA)
MLA makes KV‑cache storage cheaper, but standard attention is still quadratic in sequence length: every new token looks at all previous tokens. If you have a 100,000‑token document, the 100,001st token has to attend to 100,000 previous ones. DSA modifies this.

3.1 Intuition: From Dense to Sparse Attention
In a classic transformer:
- Each new query token attends to all previous tokens.
- Complexity: \(O(L^2)\) in both compute and memory.
In long‑context settings (\(L \gg 10^4\)), this quickly becomes infeasible. Many recent models therefore restrict attention using sliding‑window attention, where each token attends only to a fixed local window of size \(w\).
Sliding‑window attention reduces the complexity to \(O(L \cdot w)\), but it may lose long‑range dependencies because distant but semantically important tokens fall outside the window.
DSA keeps the idea of “only look at some tokens” but makes the subset learned and content‑aware, not just a fixed local window.
3.2 Components: Lightning Indexer and Token Selector
DSA consists of two components that operate on top of MLA:
- Lightning indexer: for each new query token, it computes a quick relevance score to every previous token. It operates in the compressed MLA space, so it is very cheap to run.
- Token selector: it takes the relevance scores from the indexer and selects only the top‑\(k\) tokens (for example, \(k = 2048\)). The model then builds a sparse attention mask, effectively ignoring everything else.
You can imagine the indexer as a very fast “search engine” over the past tokens, and the token selector as the “top results” page. Only those top results are exposed to the full, expensive attention.
3.3 Lightning Indexer: Mathematical Sketch
The paper defines the indexer similarity score \(I_{t,s}\) between a current query token \(t\) and a past token \(s\) as
$$
I_{t,s} = \sum_{j=1}^{H^I} w_{t,j} \, \mathrm{ReLU}\left(q_{t,j} \cdot k_s\right)
$$
where
- \(H^I\) is the number of indexer heads.
- \(w_{t,j}\) is a learned per‑head weight for the current token.
- \(q_{t,j}\) is the query vector for head \(j\) at position \(t\).
- \(k_s\) is the MLA‑compressed key vector at position \(s\).
Important aspects:
- The indexer only runs over queries; keys are already stored in the MLA cache.
- The ReLU keeps only positive dot products; negative similarities are zeroed.
- Sparsity comes not directly from ReLU but from the top‑\(k\) selector that follows.
By using this mechanism, the heavy attention step only runs on a small number of selected tokens. For long contexts, this turns dense attention into a form of learned, content‑aware sparse attention.
3.4 Complexity: From Quadratic to Linear in Practice
Conceptually, the overall cost with DSA is
- Lightning indexer: \(O(L^2)\) but extremely light‑weight (few heads, low precision, small matrices operating in the latent space).
- Main attention: \(O(L \cdot k)\), since each query only attends to \(k\) selected tokens.
For long sequences where \(k \ll L\), almost all heavy compute moves from dense attention into the much cheaper indexer, so effective end‑to‑end complexity is close to \(O(L \cdot k)\). This is what enables
- 128k‑token contexts that are actually usable.
- 2–3× speed‑ups over dense attention on long contexts, together with lower memory usage in practice.
3.5 How DSA Is Trained: Two‑Stage Integration
Switching a large model from full to sparse attention cannot be done naively; otherwise, you risk breaking learned behaviors. DeepSeek V3.2 inherits the DSA training strategy from V3.2‑Exp, which proceeds in two stages.
Stage 1: Dense Warm‑Up
- Start from the DeepSeek V3.1‑Terminus checkpoint.
- Introduce the lightning indexer but keep the main model (dense attention) fixed.
- Train the indexer for a relatively small number of tokens (≈2.1B) so that it learns to imitate dense attention patterns.
Intuitively, the indexer learns: “given the current query and all past tokens, which tokens would dense attention mostly care about?”
Stage 2: Sparse Training
Once the indexer is trained:
- Enable the top‑\(k\) token selector (for example, \(k = 2048\)).
- Switch the main attention mechanism to use the sparse mask.
- Train the entire model further (≈944B tokens) under this sparse regime.
At this stage, the model gradually adapts to using sparse attention without catastrophic drops in performance. The underlying post‑training pipeline is kept aligned with V3.1‑Terminus to make comparisons fair.
From an engineering standpoint, this two‑stage approach gives you a recipe: if you have a dense long‑context model today, you can warm‑start a sparse indexer on top of it rather than re‑training from scratch.
4. DeepSeekMath V2: Self‑Verification and Self‑Refinement
DeepSeek V3.2 incorporates a powerful training technique from DeepSeekMath V2: self‑verification with self‑refinement. DeepSeekMath V2 serves as a proof‑of‑concept that these ideas work at scale for math reasoning.
4.1 Motivation: Beyond “Correct Answer Only” Rewards
Reinforcement Learning with Verifiable Rewards (RLVR) focuses on verifiable end results:
- Use external tools (for example, a math solver or code interpreter) to check whether the final answer is correct.
- Reward the model if the answer is correct; penalize otherwise.
However, this has two key limitations:
- A model can get the right answer via flawed reasoning.
- Many tasks (for example, theorem proving) require rigorous step‑by‑step proofs, not just a final number.
DeepSeekMath V2 therefore introduces an additional layer of supervision: LLM‑based proof verification. The setup involves three models during training:
- The student (proof generator): attempts to write a rigorous mathematical proof.
- The professor (verifier): grades the proof. It assigns a score not just on the answer, but on the logic (1.0 for rigorous, 0.5 for minor errors, 0.0 for fundamentally flawed).
- The dean (meta‑verifier): checks whether the professor is grading correctly, ensuring the feedback loop remains stable.
Training steps (simplified):
- Start from DeepSeek V3.2‑Exp‑SFT (a supervised fine‑tuned reasoning model).
- Train the verifier with RL so that its scores match human‑annotated scores.
- Use the meta‑verifier to further improve the verifier’s analysis quality.
This setup is reminiscent of GANs:
- The proof generator plays the role of a generator.
- The verifier and meta‑verifier together act like sophisticated discriminators.
The result is a verifier that is strong enough to judge intermediate proof steps, not just final answers.
4.2 Self‑Refinement
During training, this trio (student, professor, and dean) works together to improve the model. During inference, the deployed model uses self‑refinement:
- Generate an initial proof.
- Critique the proof against an internal rubric (for example, looking for missing steps or logical gaps).
- Generate a refined proof that addresses the critique.
In earlier self‑refinement work, the same LLM was often used both to generate and to critique, which can lead to lenient self‑judgement. The DeepSeek setup first trains a separate, stronger verifier and meta‑verifier, and then distills their behavior back into a single proof‑generator model.
DeepSeek V3.2 reuses this recipe for its math domain rewards, allowing it to achieve gold‑level performance on math competitions by internalizing this rigorous self‑critique process.
5. Reinforcement Learning in V3.2
DeepSeek V3.2 continues the RLVR tradition from R1 but generalizes it to cover reasoning, agentic tasks, and general chat.
5.1 From Pure RLVR to a Hybrid Reward Setup
In DeepSeek R1, the RL pipeline used three main rewards:
- Format reward: ensure the answer follows a specific format.
- Language consistency reward: avoid switching languages mid‑answer.
- Verifier reward: check correctness via symbolic tools (math solvers, compilers).
For V3.2, rewards are rebalanced and extended:
- Reasoning and agent tasks:
- Rule‑based outcome reward: task‑specific checks (for example, passing tests, solving a puzzle, satisfying tool‑use constraints).
- Length penalty: discourage overly long, meandering answers, which is important for agents that might otherwise “think forever.”
- Language consistency reward: keep responses coherent and in the correct language.
- General tasks (no symbolic verifier):
- Use a generative reward model (an LLM‑as‑a‑judge) that scores responses against per‑prompt rubrics.
For math, DeepSeek V3.2 additionally reuses the DeepSeekMath V2 self‑verification rewards, so it benefits from the more nuanced proof supervision discussed in the previous section.
From a practitioner’s point of view, the important takeaway is that V3.2 is not only rewarded for “getting the answer right,” but also for formatting, conciseness, language discipline, and tool‑use behavior, depending on the task type.
5.2 GRPO and Its Refinements in V3.2
GRPO (Group Relative Policy Optimization) is the policy‑optimization algorithm introduced by DeepSeek for RLVR. Since R1, many papers (for example, DAPO and Dr. GRPO) have proposed modifications for stability and efficiency. DeepSeek V3.2 selectively adopts some ideas while staying closer to original GRPO than some of these variants.
Key GRPO‑related design choices in V3.2 include
- Domain‑specific KL strengths:
- Instead of always dropping KL regularization, V3.2 keeps a KL term but tunes its weight per domain.
- For math, the KL weight is often very weak or near zero to allow more aggressive policy updates.
- Unbiased KL estimate:
- The KL penalty is reweighted using the same importance ratio as the main loss.
- This makes the KL gradient consistent with the fact that rollouts come from the old policy.
- Off‑policy sequence masking:
- During training, rollout data are reused for multiple gradient steps.
- If a generated sequence has negative advantage (too far from what the current model would produce), it is dropped from training to prevent instability.
- This avoids learning from overly stale or off‑policy rollouts.
- Keep routing for MoE models:
- When recording rollouts, the system also records which MoE experts were chosen.
- During training, it forces the same routing pattern so gradients update exactly the experts that produced the sampled answers.
- Keep sampling mask for top‑\(p\) / top‑\(k\):
- If rollouts used top‑\(p\) or top‑\(k\) sampling, the sampling mask is stored.
- The same mask is applied when computing GRPO loss and KL, so the action space at training time matches what was actually available during sampling.
The result is a GRPO variant that is more stable and physically consistent with the sampling process, while remaining close in spirit to the original RLVR formulation.
6. V3.2‑Speciale: Extended‑Thinking Variant
On top of the main DeepSeek V3.2 model, the team also releases DeepSeek V3.2‑Speciale, a high‑compute, extended‑thinking variant.
Key characteristics
- Reasoning‑only RL: during RL, Speciale is trained mainly on reasoning data, similar in spirit to R1.
- Reduced length penalty: the RL length penalty is weakened so that the model is allowed to generate substantially longer chains of thought.
- Inference scaling: longer outputs mean higher inference cost, but better accuracy on challenging benchmarks.
Empirically, Speciale achieves
- Gold‑level performance on high‑end math and informatics benchmarks (for example, IMO‑ and IOI‑style tasks).
- Performance matching or surpassing GPT‑5‑class systems on several reasoning benchmarks, at the cost of more generated tokens per answer.
You can think of the “regular” V3.2 model as the practical deployment workhorse, while Speciale explores the limits of what the architecture can do when given more inference budget.
7. Capabilities and Use Cases
DeepSeek V3.2 is designed for real‑world deployment, not just benchmarks. In practice, three capability clusters matter most: long‑context applications, agentic workflows, and thinking‑aware context management.
7.1 Long‑Context Applications
Thanks to the combination of MLA (memory efficiency) and DSA (compute efficiency), V3.2 excels at
- Document assistants: reasoning over hundreds of pages or multiple PDFs in a single context window.
- Codebase‑scale reasoning: reading and modifying large repositories without overly aggressive chunking.
- Conversation history: maintaining long, coherent multi‑session chats.
If you are building a system that needs to keep many files or long conversations “in mind” at once, V3.2’s architecture directly targets this use case.
7.2 Agentic Workflows
V3.2 is explicitly trained as an agent backbone:
- Integrated reasoning plus tool calls: the model can interleave chain‑of‑thought reasoning with external actions (for example, code execution, search, API calls).
- Persistent reasoning state: intermediate reasoning can be preserved across tool calls until a new user prompt resets the context.
- Large‑scale synthetic task generation: the training pipeline synthesizes many agentic tasks (coding, search, interactive problem solving) to teach the model to orchestrate tools.
Representative use cases include
- Multi‑step coding workflows (write → run → debug → refine).
- Research agents that query the web, read documents, and summarize findings.
- Complex data‑processing or ETL agents that coordinate multiple tools.
7.3 Thinking‑Aware Context Management
DeepSeek R1 demonstrated that adding an explicit thinking phase (for example, chain‑of‑thought style reasoning) can dramatically improve performance on complex problems. However, naively carrying this over to tool‑calling settings leads to severe token inefficiency: if the model has to re‑generate its entire chain of thought after every tool call, the cost of long agent runs becomes prohibitive.
DeepSeek V3.2 therefore introduces a thinking‑aware context management policy specifically for tool‑using agents:
- Retain thinking across tool calls: once the model has produced a reasoning trace and initiated a tool call, the intermediate chain of thought is kept in the context as long as no new user message arrives. Tool outputs and follow‑up tool calls are simply appended on top of the existing thoughts.
- Reset thinking only on new user turns: when a new user message is introduced (for example, a fresh question or a major correction), the previous reasoning trace is removed to avoid confusion and drift. Crucially, the history of tool calls and their results is preserved, so the model can still build on past actions without re‑executing tools.
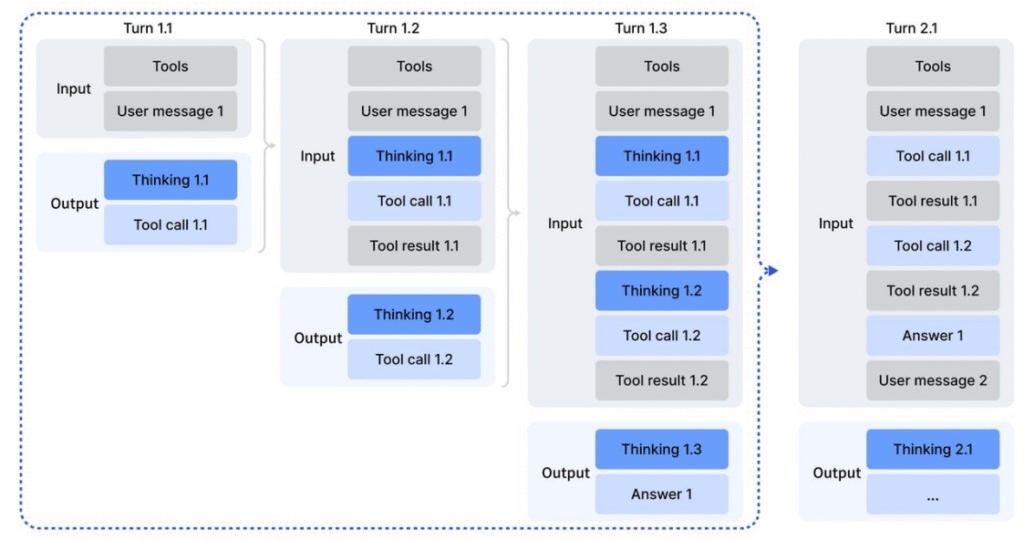
Intuitively, you can think of the conversation state as having two layers:
- A stable tool‑interaction log: the sequence of tool invocations and their outputs.
- A transient thinking scratchpad: the model’s current chain of thought, which can be refreshed when the user meaningfully changes the task.
This design achieves two goals at once:
- Token efficiency: the model does not need to repeatedly “re‑think” past steps between tool calls.
- Safety and clarity: when the user provides new instructions, stale reasoning is cleared so that the model does not anchor too strongly on an outdated mental plan.
7.4 Strengths and Remaining Gaps
From reported benchmarks and public analyses, DeepSeek V3.2 offers
- Strengths
- Near‑frontier performance on many reasoning and agentic benchmarks.
- Strong math and code skills, especially in Speciale.
- Competitive tool‑use performance, often matching or exceeding GPT‑based baselines on complex agent tasks.
- Attractive cost–performance trade‑off due to sparse attention and hardware‑optimized kernels.
- Limitations
- World knowledge may lag behind top proprietary models, given finite pre‑training compute and data.
- Token efficiency is not perfect: long chains of thought are powerful but can be verbose.
- On the very hardest reasoning problems, some closed models may still hold a small edge.
8. Why DeepSeek V3.2 Matters
DeepSeek V3.2 is significant for at least three reasons.
- Engineering‑first long‑context design.
- Instead of simply making the model bigger, DeepSeek attacks the quadratic attention bottleneck with MLA and DSA.
- This makes 128k‑token contexts more than a marketing number; they are actually usable in practice.
- Bridging open and closed models.
- Performance gaps to top proprietary systems are now measured in small margins, not in entire capability tiers.
- For many workloads, especially long‑context and agentic ones, V3.2 is “good enough” while being open‑weight.
- Template for future models.
- Techniques like sparse or dynamic attention, specialist‑to‑generalist distillation, and integrated tool‑use training are likely to become standard.
- DeepSeek V3.2 provides a concrete, open example of how to combine these ideas at scale.
For practitioners building document assistants, coding agents, or multi‑step reasoning systems, DeepSeek V3.2 offers a compelling foundation: long context, strong reasoning, and a training recipe that is explicitly optimized for real‑world deployment.
DeepSeek V3.2 represents a shift from “bigger is better” to “smarter is better.” By combining the memory compression of MLA, the selective attention of DSA, and rigorous self‑verification training, it delivers frontier‑class performance in an open‑weight package.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!