Designing an AI system often feels like choosing how to travel from Point A to Point B. The destination is fixed (your business outcome), but you can walk, drive, or fly to get there. This article is a practical compass to help you decide when to use rules, traditional ML, or Generative AI – and how to justify that choice.
The Intuition: Walking, Driving, and Flying
Imagine you need to travel from Point A to Point B. How do you choose your mode of transport?
- Walking (Rule-Based): It is free, reliable, and you have total control. But it does not scale well for long distances.
- Driving (Predictive ML): It is faster and can handle complex routes, but you need fuel (data) and a license (training).
- Flying (Generative AI): It can take you anywhere, even across oceans (open-ended tasks), but it is expensive, requires massive infrastructure, and you have less control over the exact path.
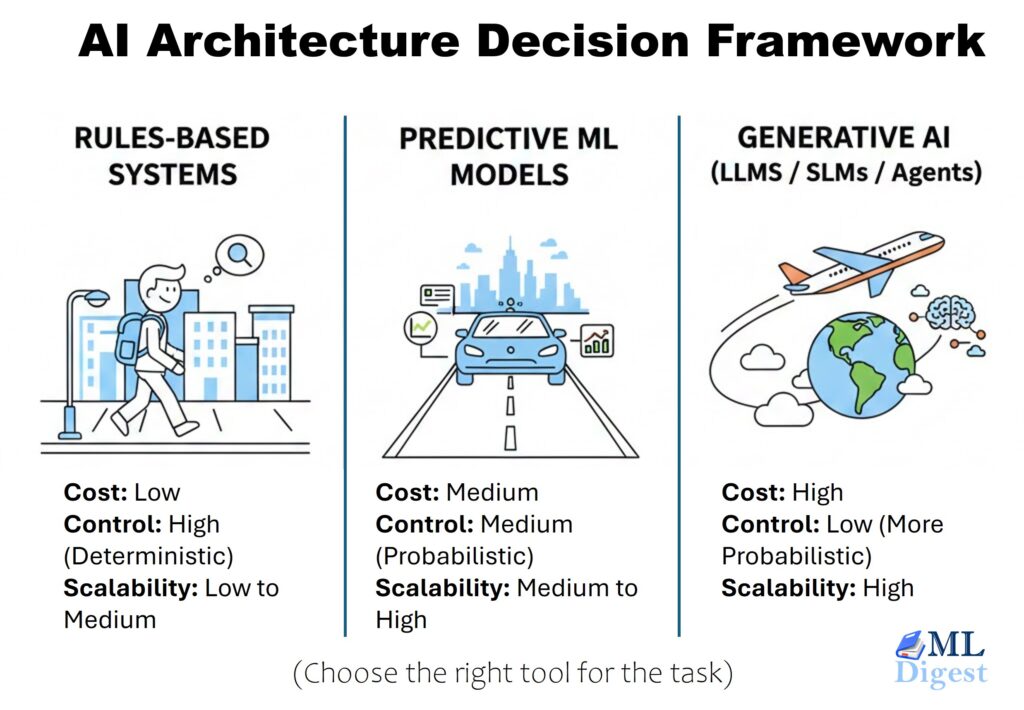
In AI architecture, we face the same choice. Teams often rush to “fly” (GenAI) when “walking” (Rules) would have been faster and cheaper. The goal of this guide is to provide a clear, repeatable framework for deciding between:
You can think of this as an AI solution-class decision playbook that fits into your PRDs, architecture reviews, and technical design docs.
This article provides:
- A decision flow (Mermaid diagram) to pick a solution class.
- A set of dimensions to compare options when the answer is not obvious.
- A weighted decision matrix to break ties and document trade-offs.
Solution Class Decision Flow: Rule-Based vs ML vs GenAI
As a default, start as simple as possible. Many high-impact AI features are better served by deterministic logic or small, traditional ML models than by LLMs.
This section gives a decision flow and a scoring matrix to choose responsibly.
flowchart TD
start[Start: Define Problem and Constraints] --> output_mapping{Output Type / Mapping}
output_mapping -- 1:1 --> deterministic{Deterministic transform; rules known?}
output_mapping -- Closed output set (class/score; N:1, 1:N) --> data_available{Labeled data and objective metrics?}
output_mapping -- Open-ended content (sequence/image/code; M:N) --> genai[Generative AI]
data_available -- Yes --> predictive_ml[Predictive ML]
data_available -- No --> E[Revisit Data Strategy / Reframe Problem]
deterministic -- Yes --> rule_based[Rule-Based System]
deterministic -- No --> predictive_ml
predictive_ml --> nfr_ok{Latency/Cost/Explainability OK?}
nfr_ok -- Yes --> DeployML[Deploy ML MVP]
nfr_ok -- No --> Compress[Distill/Quantize/Optimize or Hybrid]
genai --> llm_data_available{Enough labeled data?}
llm_data_available -- Yes --> general_purpose_LLM_ok{Does General-Purpose LLM work?}
general_purpose_LLM_ok -- Yes --> prompting
general_purpose_LLM_ok -- No --> LLM_finetune[LLM/SLM Fine-Tuning]
llm_data_available -- No --> prompting{Zero/Few-Shot Prompting}
prompting -- Simple task --> SLM
prompting -- Complex task --> LLM
LLM -- Latency/Cost NOT OK? --> distill[SLM finetuning + Distillation]Interpretation:
- Prefer rule-based systems when logic is stable and explicit. They are fast, cheap, and explainable.
- Prefer traditional ML when you have labeled data and objective metrics.
- Prefer GenAI when the task involves understanding or generating unstructured content or complex reasoning.
- Any path should respect non-functional constraints; if not, reframe or hybridize.
The Dimensions of Choice
When the mapping is not obvious from the flowchart, use the dimensions below as a checklist in your design document. For each dimension, ask:
“On this axis, does Rule-Based, ML, or GenAI have a clear advantage for my problem?”
Input → Output Mapping Dimension
Use this dimension first: understanding how inputs relate to desired outputs quickly narrows viable solution patterns (rules vs classical ML vs GenAI).
| Mapping (Input→Output) | Description | Examples | Recommendation |
|---|---|---|---|
| Deterministic transform 1:1 | Each input maps to exactly one output through a clear, rule-based transformation. | Data normalization, parsing, validation tasks where rules can be explicitly defined. | Rule Based |
| Non-deterministic transform 1:1 | Each input maps to exactly one output, but the transformation is complex and not easily defined by rules. | Remaining useful life estimation or customer lifetime value regression. | Predictive ML |
| N:1 closed output | Multiple inputs map to a single output from a predefined set of labels. | Credit risk assessment, churn prediction tasks where outputs are categorical but require more complex modeling. | Predictive ML |
| 1:N closed output | A single input maps to multiple outputs from a predefined set of labels. | Multi-label classification tasks like tagging, categorization where each input can belong to multiple categories. | Predictive ML |
| M:N open output | Multiple inputs map to a multiple outputs. | Customer support responses, content generation tasks where outputs are unstructured text. | Generative AI |
Think of every system as a mapping \(y = f(x)\). The nature of this mapping, especially the output domain, guides the simplest viable solution.
- One-to-one, one-to-many, many-to-one, and many-to-many describe the structure of inputs and outputs for a request, not whether a solution is rule-based or learned.
- Rule-based systems can implement any mapping when rules are explicit and stable (both \(1 \to 1\) and \(N \to 1\)). Choose rules when determinism, auditability, and low latency dominate.
- Traditional predictive ML typically maps rich inputs to a closed output space (a finite label set or numeric value). Common patterns:
- \(N \to 1\): classification or regression from many features to one label or value. \(1 \to N\) or multi-output: multi-label tagging.
- Generative modeling targets open-ended, high-dimensional outputs (variable-length text, images, code). This is often \(M \to N\) (sequence-to-sequence or content synthesis) with stochasticity. Evaluation emphasizes quality, fidelity, grounding, and safety over exact class accuracy.
Practical guidance:
- If the output space is closed and easily testable (label, score, bounded fields), prefer rules or predictive ML.
- If the output must be novel, long-form, or highly structured beyond a small schema, prefer GenAI with guardrails (RAG, schema-constrained decoding).
- A \(1 \to N\) result list from retrieval is a search or ranking task, not generation. Exhaust standard retrieval and ranking approaches before using GenAI.
- You can constrain a generative model to behave like a classifier; do this only when you need its understanding and simpler models cannot meet quality.
Scenarios:
- Deterministic transforms (normalize, validate, extract) → rules or regex.
- Noisy but closed-target mapping (risk score, route) → predictive ML; consider abstaining when uncertain.
- Long-form content (summaries, drafts, translations) → GenAI with grounding and safety.
Data Availability State Dimension
Data availability is a key factor in determining the feasibility of different modeling approaches.
| Mapping (Input→Output) | Labelled Data Availability | Description | Recommendation |
|---|---|---|---|
| Deterministic transform 1:1 | Any (rules suffice) | Sufficient data to define clear rules. | Rule Based |
| Non-deterministic 1:1 or 1:N or N:1 | Low (<1k noisy) | Limited data, possibly noisy or incomplete. | Start Rule Based → Predictive ML interpretable |
| Non-deterministic 1:1 or 1:N or N:1 | Medium (1k–100k) | Moderate amount of data, some quality concerns. | Predictive ML interpretable (linear, tree-based, etc.) |
| Non-deterministic 1:1 or 1:N or N:1 | High (>100k) | Acceptable data quality with high quantity. | Predictive ML (non-linear, ensemble methods, small NN) |
| M:N open output | Low (<1k noisy) | Limited data, possibly noisy or incomplete. | Zero-shot or few-shot prompting with LLM (for complex tasks) or SLM (for simpler tasks) |
| M:N open output | Medium (1k–100k) | Moderate amount of data, some quality concerns. | Parameter efficient Fine-tuned SLM |
| M:N open output | High (>100k high quality) | Large, high-quality dataset available. | Fully Fine-tuned SLM + Distillation |
Latency Dimension
Latency requirements can significantly influence model choice, especially in real-time applications.
| Modeling Approach | Typical Latency Range | Description | Recommendation |
|---|---|---|---|
| Rule Based | < 10 ms | Simple lookups and transformations. | Use for low-latency needs. |
| Predictive ML (small models) | 10 ms – 100 ms | Moderate complexity with some processing overhead. | Optimize for speed; consider model distillation. |
| Predictive ML (large models) | 100 ms – 500 ms | Higher complexity with significant processing requirements. | Use model quantization and efficient architectures. |
| Generative AI (NLP models, SLM) | 100 ms – 1 s | High complexity with significant processing requirements. | Use caching and batching to improve latency. |
| Generative AI (LLM) | 2 s – 4 s | Very high complexity, often requiring substantial computational resources. | Use for non-real-time applications or with significant optimization. |
| Generative AI (LLM with retrieval; reasoning models) | 4 s – 10 s | Extremely high complexity, often requiring multiple model calls and external data access. | Use for non-real-time applications only. |
| Generative AI (Agentic systems, LLM with tool use) | 10 s – 30 s | Very high complexity, often requiring multiple model calls and external data access. | Use for non-real-time applications only. |
Cost Dimension
Cost considerations are crucial, especially for large-scale deployments.
| Modeling Approach | Typical Cost Range per Request | Description | Recommendation |
|---|---|---|---|
| Rule Based | negligible | Minimal computational resources required. | Use for cost-sensitive applications. |
| Predictive ML (small models) | very low | Moderate computational resources required. | Optimize model size and inference efficiency. |
| Predictive ML (large models) | low | Higher computational resources required. | Use for applications where accuracy justifies cost. |
| Generative AI (NLP models, SLM) | low | Significant computational resources required. | Use for applications where quality justifies cost. |
| Generative AI (LLM) | high | Very high computational resources required. | Use for specialized applications only. |
| Generative AI (LLM with retrieval; reasoning models) | very high | Very high computational resources required. | Use for specialized applications only. |
| Generative AI (Agentic systems, LLM with tool use) | highest | Very high computational resources required. | Use for specialized applications only. |
Explainability Dimension
Explainability is often a regulatory or business requirement, especially in high-stakes applications.
| Modeling Approach | Typical Explainability Level | Description | Recommendation |
|---|---|---|---|
| Rule Based | High | Clear, rule-based logic. | Use for applications requiring transparency. |
| Predictive ML (interpretable models) | Medium | Somewhat interpretable, especially with techniques like SHAP or LIME. | Use for applications needing some level of explainability. |
| Predictive ML (complex models) | Low | Difficult to interpret, especially with deep learning models. | Use for applications where accuracy is prioritized over explainability. |
| Generative AI (SLM) | Low | Difficult to interpret, especially with deep learning models. | Use for applications where accuracy is prioritized over explainability. |
| Generative AI (LLM) | Very Low | Very difficult to interpret due to model complexity. | Use for applications where accuracy is prioritized over explainability. |
| Generative AI (LLM with retrieval; reasoning models) | Very Low | Very difficult to interpret due to model complexity. | Use for applications where accuracy is prioritized over explainability. |
| Generative AI (Agentic systems, LLM with tool use) | Very Low | Very difficult to interpret due to model complexity. | Use for applications where accuracy is prioritized over explainability. |
Putting It All Together
Use the provided tables to guide model selection based on the combined dimensions of input-output mapping, data availability, latency, cost, and explainability needs.
In practice:
- Start with Input → Output Mapping to narrow down candidate solution classes.
- Check Data Availability to see what is actually feasible.
- Stress-test candidates against Latency, Cost, and Explainability.
- Consider hybrid approaches where appropriate, such as starting with rule-based systems and augmenting with ML models as data becomes available, or wrapping GenAI with rules for safety.
- Continuously monitor model performance and constraints, adjusting as requirements, usage, or data availability change.
The Tie-Breaker: The Weighted Decision Matrix (Scoring)
Sometimes, looking at individual dimensions like latency or cost in isolation does not yield a clear winner. You might find yourself in a situation where GenAI offers the best performance, but Rule-Based systems offer the necessary safety. How do you resolve this conflict in a way that is explicit and defensible?
Think of this process like choosing a university. You do not just pick the one with the best campus. You weigh multiple factors: tuition cost, distance from home, prestige of the specific program you want, and campus culture. For one student, cost might be the dominant factor (weight = 0.5). For another, the specific program prestige is paramount (weight = 0.6). The “best” choice is subjective to your constraints.
In AI architecture, you can formalize this subjectivity using a Weighted Decision Matrix. This tool forces you to assign numerical values to your priorities, turning a vague debate into a calculable score.
Example factors:
- Performance (low = 1; high = 5)
- Latency (low = 5; high = 1)
- Cost per request (low = 5; high = 1)
- Explainability/Auditability (low = 1; high = 5)
- Safety Risk (low = 5; high = 1)
- Data Availability (low = 1; high = 5)
- Development Time (low = 1; high = 5)
- Maintenance Complexity (low = 5; high = 1)
- Business Fit (low = 1; high = 5)
Score each candidate (Rule, ML, GenAI) from 1–5 and weight factors according to your domain. The winner is the highest weighted score. Keep the matrix in your PRD or design doc to justify the choice and as a baseline for future pivots.
Example (illustrative):
| Factor | Weight | Rule | ML | GenAI |
|---|---|---|---|---|
| Performance | 0.2 | 4 | 5 | 3 |
| Latency | 0.2 | 5 | 4 | 2 |
| Cost | 0.2 | 5 | 4 | 2 |
| Explainability | 0.1 | 5 | 3 | 2 |
| Safety Risk | 0.1 | 5 | 4 | 2 |
| Data Availability | 0.05 | 2 | 4 | 4 |
| Development Time | 0.05 | 4 | 3 | 3 |
| Maintenance Complexity | 0.05 | 4 | 3 | 3 |
| Business Fit | 0.05 | 3 | 4 | 5 |
| Weighted Score | 4.1 | 3.8 | 2.9 |
In the above example, Rule-Based wins due to its high scores in critical factors like Latency, Cost, Explainability, and Safety Risk.
Conclusion: From Compass to Concrete Decision
Do not use a cannon to kill a mosquito. The point of this framework is not to glorify complex models but to match solution class to problem.
You can turn this article into a practical checklist for every new AI feature:
- Start with Rules: If you can write a regex or a few clear business rules, do it first.
- Upgrade to ML: If the rules get too complex (spaghetti code) or performance plateaus, train a predictive model.
- Unlock GenAI: If the problem requires synthesis, reasoning over unstructured content, or handling the “long tail” of edge cases, use an LLM or SLM, ideally with grounding and guardrails.
- Document the decision: Capture the flowchart path you took and the weighted matrix in your PRD so that future teams understand why you chose Rules, ML, or GenAI.
Over time, this compass helps you build AI systems that are cheaper, safer, and easier to maintain, while keeping GenAI reserved for the problems where it truly shines.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!