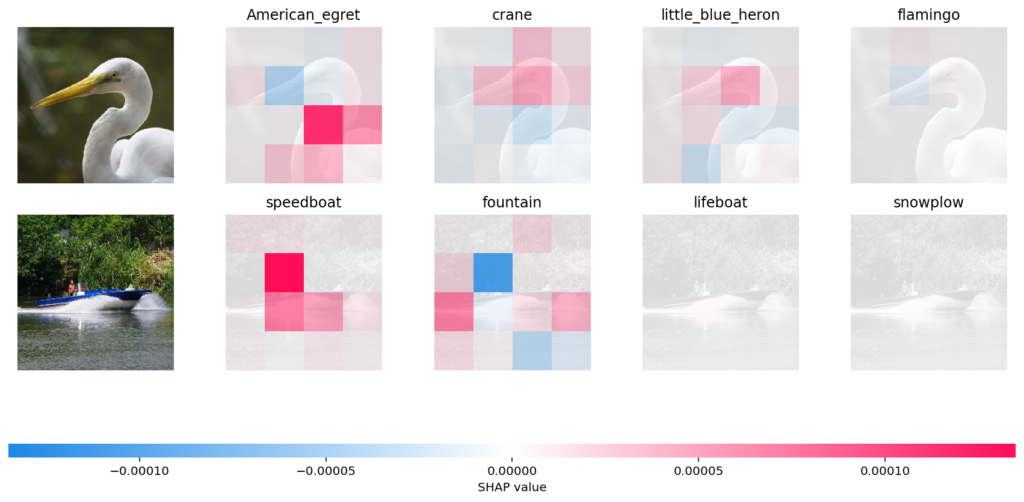The variance of a Random Forest (RF) is a critical measure of its stability and generalization performance. While individual decision trees often have high variance (being sensitive to small changes in the training data), a Random Forest, as an ensemble method, significantly reduces this through averaging. The reduction in variance, however, is heavily influenced by the correlation between the individual trees.
Intuition: A Crowd of Weather Forecasters
Imagine you ask 100 hobby weather forecasters to predict tomorrow’s temperature. If each person looks at exactly the same website and uses the same simple rule, their predictions will be very similar. Averaging them barely reduces uncertainty — their errors are highly correlated. Now imagine each forecaster uses different data sources, focuses on different atmospheric signals, and applies their own quirky heuristics. Individual predictions bounce around more (higher individual variance), but crucially, their errors are now less aligned. When you average these diverse, only weakly correlated predictions, the wild swings cancel out and the ensemble becomes stable. This is the Random Forest story: keep single trees wild (high variance) while making their errors disagree (low correlation). The remaining variance after “infinite” averaging is the part they agree on — the correlated component.
The Relationship Between Variance, Correlation, and Tree Count
The core idea can be encapsulated by the formula for the variance of an average of \(T\) predictors, \(\text{Var}(\bar{f})\), where \(f_i\) is the prediction of the \(i\)-th tree and \(\bar{f}\) is the ensemble prediction:
$$\text{Var}(\bar{f}) = \rho \sigma^2 + \frac{1-\rho}{T} \sigma^2$$
Where:
- \(\sigma^2\) is the average variance of a single tree’s prediction.
- \(\rho\) is the average pairwise correlation between the predictions of any two distinct trees.
- \(T\) is the number of trees in the forest.
This formula shows that the ensemble’s variance is comprised of two parts: a correlation-dependent term and a tree-count-dependent term.
Deriving the Formula
Start with the average prediction: \(\bar{f} = \frac{1}{T} \sum_{i=1}^T f_i\).
Using variance properties:
$$\text{Var}(\bar{f}) = \text{Var}\left( \frac{1}{T} \sum_{i=1}^T f_i \right) = \frac{1}{T^2} \left( \sum_{i=1}^T \text{Var}(f_i) + \sum_{i \neq j} \text{Cov}(f_i, f_j) \right).$$
Assume (standard RF variance analysis assumption):
- Each tree has the same variance: \(\text{Var}(f_i) = \sigma^2\).
- Each distinct pair has the same covariance: \(\text{Cov}(f_i, f_j) = \rho \sigma^2\) (so \(\rho\) is the average correlation).
Then:
$$\text{Var}(\bar{f}) = \frac{1}{T^2} \left( T \sigma^2 + T(T-1) \rho \sigma^2 \right)
= \frac{\sigma^2}{T} + \rho \sigma^2 \frac{T-1}{T}
= \rho \sigma^2 + (1-\rho) \frac{\sigma^2}{T}.$$
Rearranging terms yields the commonly cited form:
$$\text{Var}(\bar{f}) = \rho \sigma^2 + \frac{1-\rho}{T} \sigma^2.$$
This cleanly separates (1) the irreducible correlated component and (2) the reducible uncorrelated component.
Why Variance Drops Proportional to \(\rho \cdot \sigma^2\)
For a sufficiently large number of trees (\(T \rightarrow \infty\)), the second term, \(\frac{1-\rho}{T} \sigma^2\), approaches zero. This is the benefit of averaging independent errors. As more trees are added, the random, uncorrelated errors among them cancel out, making this term negligible.
In this asymptotic (large \(T\)) case, the variance of the Random Forest simplifies to:
$$\text{Var}(\bar{f}) \approx \rho \sigma^2$$
This is the key insight: the minimum achievable variance for the ensemble is determined by the term \(\rho \sigma^2\). The variance drops to and remains roughly proportional to the product of the average correlation (\(\rho\)) and the average single-tree variance (\(\sigma^2\)).
Edge Cases & Limits
- If \(\rho = 1\) (perfect correlation): \(\text{Var}(\bar{f}) = \sigma^2\); averaging identical trees does nothing.
- If \(\rho = 0\): \(\text{Var}(\bar{f}) = \frac{\sigma^2}{T}\); variance shrinks inversely with the number of trees.
- If \(T = 1\): recovers \(\text{Var}(f_1) = \sigma^2\).
- Diminishing returns: After some \(T\), the \(\frac{1-\rho}{T}\sigma^2\) term becomes tiny; further trees mainly cost compute.
1. The Role of Average Correlation (\(\rho\))
Correlation is the Limiting Factor. The term \(\rho \sigma^2\) represents the irremovable variance due to the fact that the errors of the individual trees are not perfectly independent.
- High \(\rho\) (High Correlation): If the trees are highly correlated (e.g., they all make similar errors because they are trained on very similar data), the ensemble variance remains high. The benefit of averaging is minimal, as averaging similar predictions still yields a similar (potentially erroneous) prediction. The ensemble variance approaches \(\sigma^2\) if \(\rho \rightarrow 1\).
- Low \(\rho\) (Low Correlation): This is the goal of Random Forests. If the trees are weakly correlated, the ensemble variance is low. The ideal scenario, \(\rho=0\), would allow the variance to drop to \(\frac{\sigma^2}{T}\), nearly eliminating variance with enough trees.
2. The Role of Single-Tree Variance (\(\sigma^2\))
High-Variance Components are Necessary. The \(\sigma^2\) term is the average variance of a single unpruned decision tree, which is typically very high (high variance, low bias).
- Random Forests rely on high \(\sigma^2\). The high variance is what allows the individual trees to be very different from one another.
- Strategy: By enforcing randomness (like Bagging and Random Subspace Method), the RF algorithm aims to keep \(\sigma^2\) high while aggressively driving \(\rho\) down. This results in an ensemble of diverse, high-variance predictors whose diverse errors cancel out when averaged, leading to a low-variance final model.
- Bias–Variance Trade-off: Fully grown trees minimize bias for many structured problems. RF reduces variance without increasing bias much — core motivation over pruning.
How Random Forests Control \(\rho\) and \(\sigma^2\)
Random Forests utilize two main randomization mechanisms to manage these components:
| Mechanism | Component Targeted | Effect |
|---|---|---|
| Bagging (Bootstrap Aggregating) | Correlation (\(\rho\)) | Training each tree on a different bootstrap sample of the data ensures that the training sets are slightly different, thereby reducing the correlation between the trees. |
| Feature Randomness (Random Subspace) | Correlation (\(\rho\)) | At each split in a tree, only a random subset of features is considered. This further decorrelates the trees, as they are prevented from all splitting on the single strongest feature, leading to a more diverse set of decision boundaries. |
| Growing Full Trees | Single-Tree Variance (\(\sigma^2\)) | Allowing the trees to grow to their maximum depth (unpruned) ensures that \(\sigma^2\) remains high, thus maximizing the diversity needed for the ensemble to work effectively. |
Practical Knobs Affecting \(\rho\) and \(\sigma^2\)
| Hyperparameter | Lowers \(\rho\) | Raises / Maintains \(\sigma^2\) | Notes |
|---|---|---|---|
max_features (smaller) | Yes | ↔ | Too small can raise bias. |
bootstrap=True | Yes | ↔ | Subsampling induces diversity. |
max_depth=None | ↔ | Yes | Deep trees keep variance high. |
min_samples_leaf (larger) | No | No | Smooths trees; may reduce both variance & diversity. |
n_estimators (larger) | Yes (effective net) | ↔ | Only helpful until correlation term dominates. |
References
- Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5–32.
- Ho, T. K. (1998). The Random Subspace Method for constructing decision forests [pdf]. IEEE TPAMI, 20(8), 832–844.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!