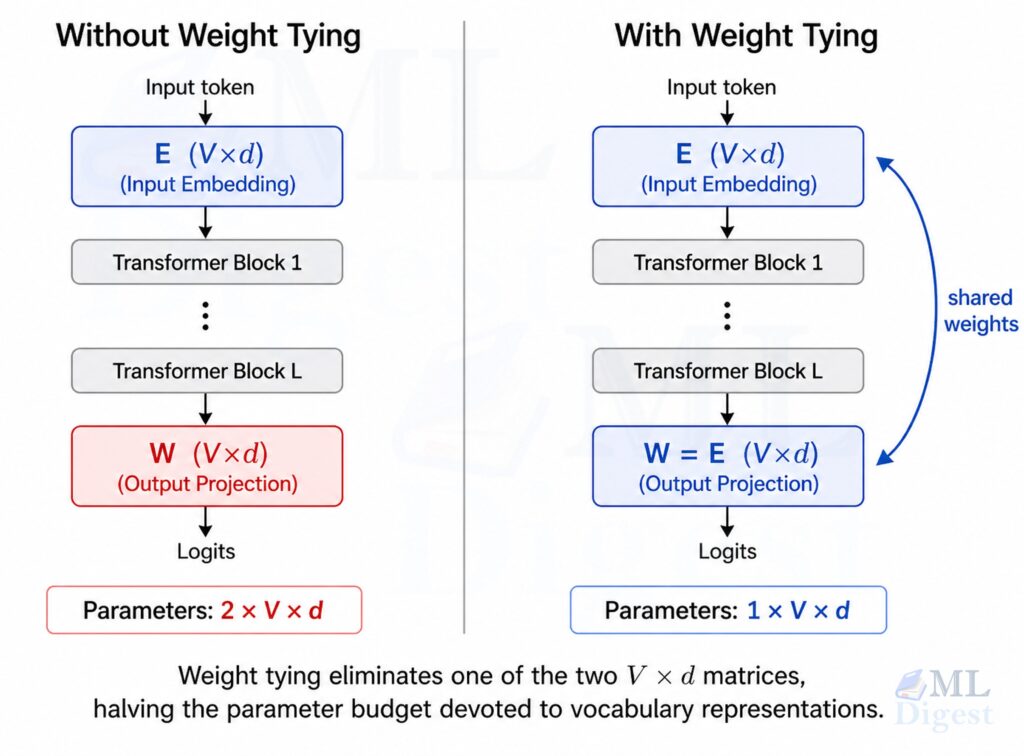
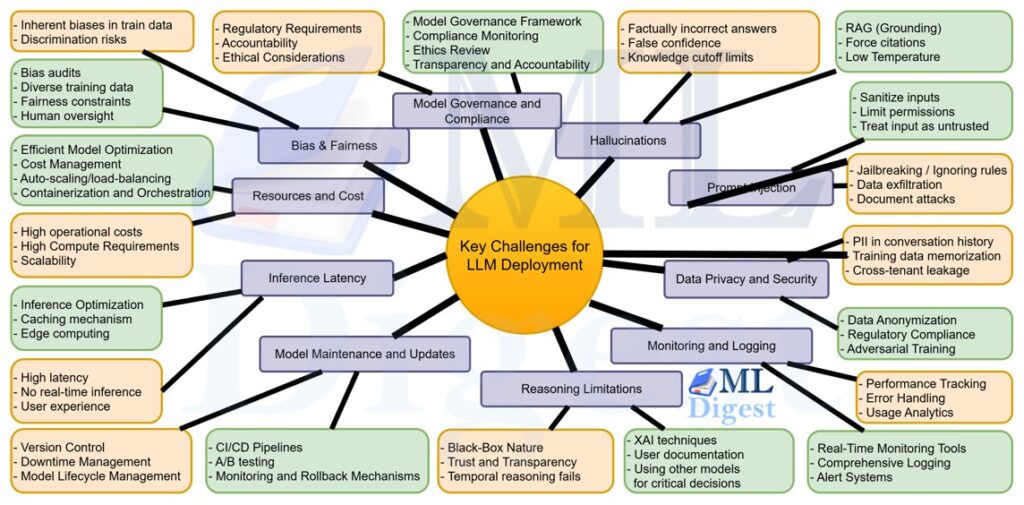
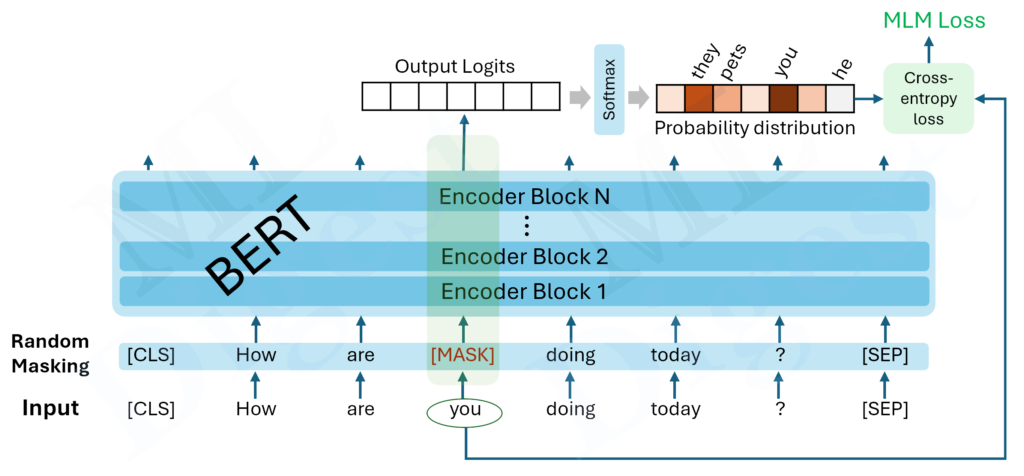
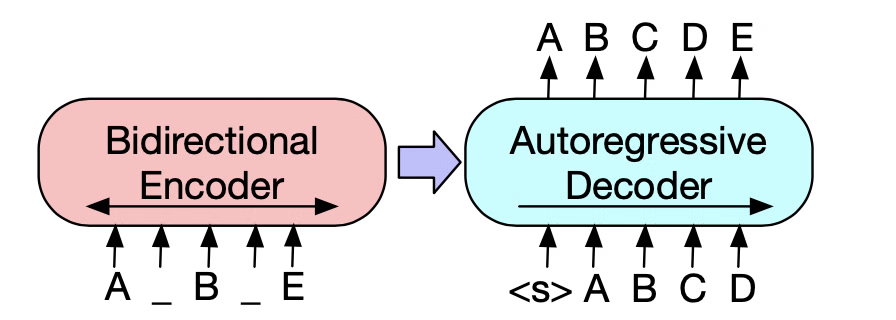
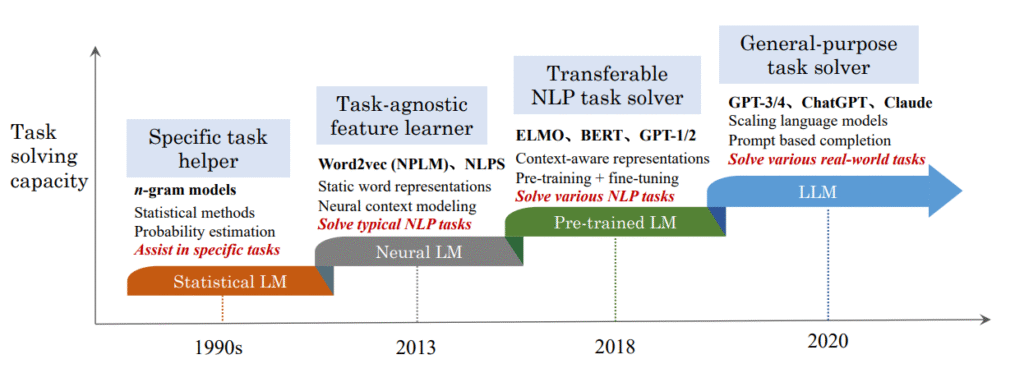
For a long time, the focus in LLM development was on pre-training. This involved scaling up compute, dataset sizes and model parameters to improve performance. However, recent developments, particularly with OpenAI’s o1 model, have revealed a new scaling law: inference time scaling. This concept involves reallocating compute from pre-training to the inference stage, allowing the AI to ‘think’ and reason for longer periods.
- Pre-training Scaling Limitations: While pre-training scaling has led to significant advancements, there are concerns about hitting a data wall in the near future. There are also questions about how much more performance can be gained by simply increasing the scale of pre-training.
- What is Inference Time Scaling? Inference time scaling means that the performance of a model can improve by increasing the amount of compute available to it during inference. This allows the model more time to ‘think’ about a problem, potentially iterating on the response to ensure accuracy. It’s a shift from the traditional focus on pre-training, where most of the compute is spent before the model is deployed.
Jim Fan summarized it well with the graphic below:

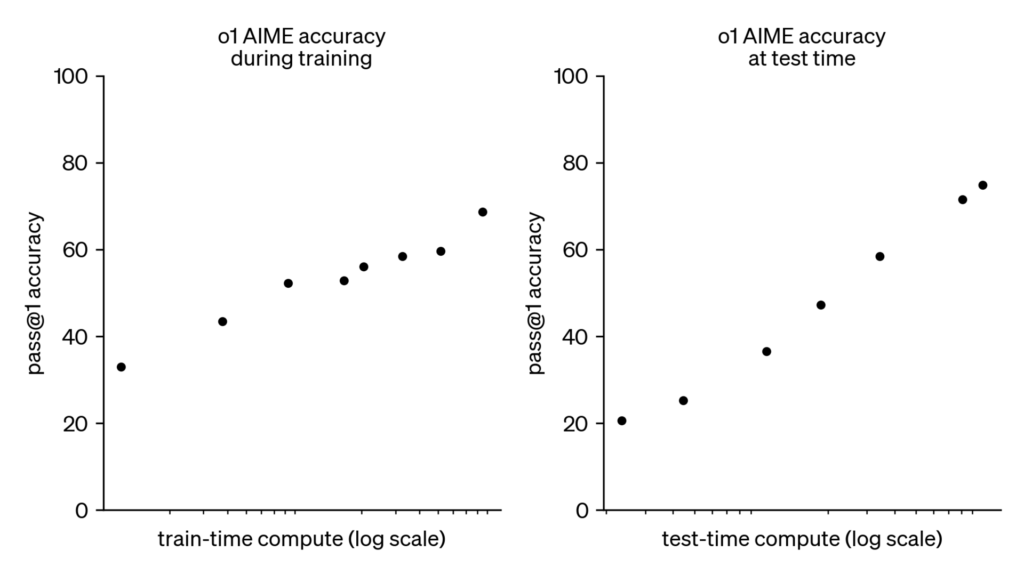
The performance of o1 model improves as inference-time compute increases (i.e., it could think for longer/harder), as shown in the below chart:
How Does it Work?
The concept of inference time scaling is closely linked to the idea of “System 1” and “System 2” thinking. System 1 is the fast, instinctive response, while System 2 is the slower, more deliberate and process-driven approach. By allowing models to think for longer during inference, they can engage in more “System 2” type reasoning. This includes using a chain of thought approach, where the model breaks down the query, reasons through it, and potentially iterates on its response. This can include reflection and using the right tools to fetch context or knowledge.
- Analogy to Human Thinking: Just as humans take longer on more complex tasks, inference time scaling allows models to spend more time and compute on difficult problems. A model could perform internal inference 10,000 times, tree search, simulation, reflection, and data look-ups before answering a question.
- Practical Implementation In practice, this can be achieved by using methods such as chain of thought prompting, which instructs the model to follow steps, reflect on outputs at each step, and use tools. Additionally, majority voting, where a model generates multiple responses and then takes a majority vote, can help with accuracy, though this has limitations.
Implications of Inference Time Scaling
The emergence of inference time scaling has several significant implications:
- More Powerful Models: This scaling approach offers a way to make models more performant without simply increasing training data or model size. It could lead to smaller pre-trained models that are highly effective at reasoning. o1 greatly improves over GPT-4o on challenging reasoning benchmarks, as shown below:

- Shift in Compute Spending (From CAPEX to OPEX): This approach is likely to cause a shift in how compute resources are allocated, with more emphasis placed on inference. This moves expenses from Capital Expenditure (CAPEX) to Operational Expenditure (OPEX), which can be directly measured and charged for.
- Directly Measurable Costs: Unlike pre-training costs, which can be somewhat fixed once a model is trained, inference-time costs are directly tied to usage. This means providers can more easily measure and track how much compute is being used for each task, making costs more transparent and controllable.
- Unlocking New Use Cases: Inference time scaling can unlock new uses for AI, especially for complex reasoning tasks, such as proving mathematical conjectures, writing large software programs or essays. It also enables models to tackle problems with higher consequences, reducing the risk of inaccuracies and hallucinations.
- Cost Effectiveness: Even with increased inference time, AI models can still be much cheaper than human workers. The scalability and constant availability of AI further enhance their cost-effectiveness.
Key Advantages
- Enhanced Reasoning
- Increased “Thinking” Time
- Better Accuracy
- Tackling Harder Problems
- More Effective Tool Use
- Reduced Errors and Hallucinations
- Flexibility and Adaptability
- Potential for Smaller Pre-trained Models
Limitations of Inference-time Scaling

- General Domain Long-Horizon Reliability: The o1 model still has limitations in terms of general domain long-horizon reliability. This means that the model may not always provide accurate or reliable responses for complex, multi-step tasks.
- Cost Implications: While inference-time scaling can improve model performance, it also comes with cost implications. Increasing the amount of compute used during inference can lead to higher operational costs, which need to be carefully managed.
- Token Budget Control: The OpenAI API, say for o1-mini, does not allow precise control over the number of tokens spent at test-time. There are work around ways to do this by instructing the model how long to “think,” but this method had its limitations.
- Performance Ceiling with Self-Consistency/Majority Vote: Unfortunately, the benefits of using self-consistency or majority voting appear to diminish significantly after an initial improvement. No major improvements are observed beyond processing around \(2^{17}\) total tokens in o1-mini. This suggest that majority voting eventually reaches a point where it no longer provides substantial gains.
Majority voting, while useful in inference-time scaling, has limitations that hinder its effectiveness beyond a certain point. Here are some of the key limitations:
- Saturation of Gains: The primary limitation of majority voting is that it does not scale indefinitely. As the number of samples increases, the performance gains begin to diminish, reaching a point where additional samples yield no significant improvements.
- Limited Performance Ceiling: Majority voting has a performance ceiling, which it cannot surpass.
- Not a Universal Solution: Majority voting is not a universal solution for improving inference-time performance. It is useful for aggregating the results of multiple model inferences, but does not solve the underlying issue of a model’s inability to reason deeply if it is limited by its initial training.
- Additional Compute Costs: While majority voting can improve the accuracy of model inferences, it is not without added compute cost. As more samples are generated, more inference time is used, which translates to increased expenses.
Inference-time scaling and pre-training scaling represent different approaches to improving the performance of LLMs. Pre-training scaling focuses on improving model performance by increasing the compute, dataset sizes, and model parameters during the initial training phase. Inference-time scaling, on the other hand, focuses on improving model performance by increasing the amount of compute available to the model during the inference stage, when the model is used to solve specific tasks.
| Inference-time scaling | Pre-training scaling |
|---|---|
| Focuses on increasing the amount of compute available to the model during inference | Focuses on increasing the compute, dataset sizes, and model parameters during the initial training phase |
| Allows the model to “think” and reason for longer periods during inference | Involves processing vast amounts of data to learn patterns and relationships during pre-training |
| Enhances performance by allowing the model to spend more time and computational resources on each specific problem it’s trying to solve | Enhances performance by increasing the model’s size and the amount of data it learns from during pre-training |
| Shifts compute spending towards operational expenditure (OPEX) | Requires substantial capital expenditure (CAPEX) for the large-scale compute resources needed for training |
| Could allow for smaller, more efficient pre-trained models that rely more on inference-time compute for reasoning | Often results in larger and more complex models |
Resources

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!