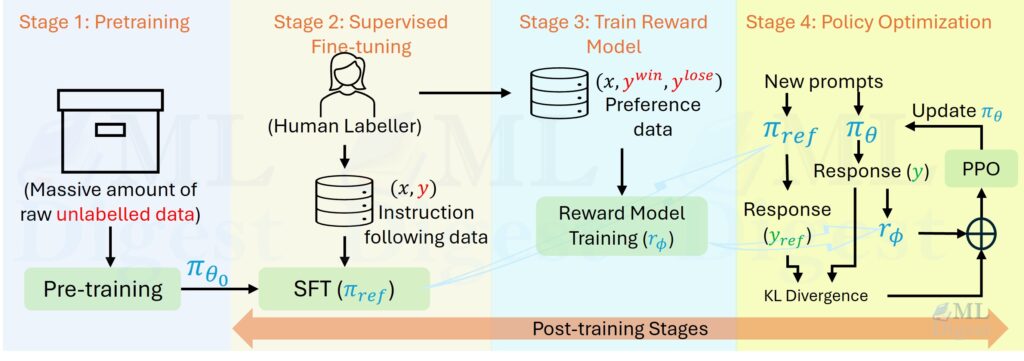
NVIDIA Cosmos is a platform that empowers developers to construct customized world models for physical AI systems at scale. It provides open world foundation models and tools for every stage of the development pipeline, from data curation to training and customization. Physical AI, which enables autonomous machines to understand, perceive, and execute complex actions in the physical world, relies on world foundation models (WFMs). These WFMs are AI models that use physics-aware videos to simulate physical states, enabling machines to interact seamlessly with their environments and make informed decisions.
The Challenges of Building Physical AI Systems
Developing physical AI systems presents significant challenges:
- The need for accurate simulations that reflect real-world physics.
- Vast amounts of data required for training these models.
- Significant computational power to process this data.
- Safety concerns and logistical hurdles of real-world testing.
To mitigate these challenges, developers often use synthetic data generated from 3D simulations for model training. However, creating this synthetic data is resource-intensive and might not always accurately represent real-world physics.
Cosmos: An End-to-End Platform
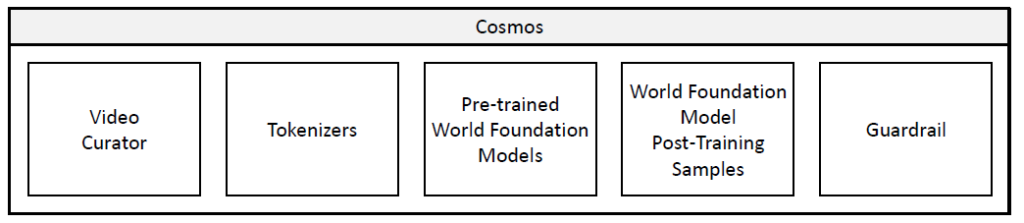
The NVIDIA Cosmos platform offers a solution to these challenges by accelerating the development of world models for physical AI systems. Built on CUDA, it combines several key components:
- State-of-the-art world foundation models: These are pretrained on vast datasets spanning autonomous driving, robotics, synthetic environments, and related domains.
- Video tokenizers: These enable efficient, compact, and high-fidelity video tokenization.
- AI-accelerated data processing pipelines: These streamline data processing and ensure high-quality training data.
- NVIDIA NeMo Framework: This framework facilitates model training and optimization.
- Guardrail: For safe usage of the developed world foundation models.
Developers can choose to fine-tune existing Cosmos world foundation models or build new ones from scratch. The platform caters to a variety of development needs.
Key Features of Cosmos

Cosmos provides several key features that facilitate the development of world models:
- Pretrained world foundation models: Cosmos offers pretrained large generative AI models, trained on vast datasets, including 20 million hours of data from relevant domains. These models are capable of generating realistic synthetic videos of environments and interactions, providing a scalable basis for training complex systems.
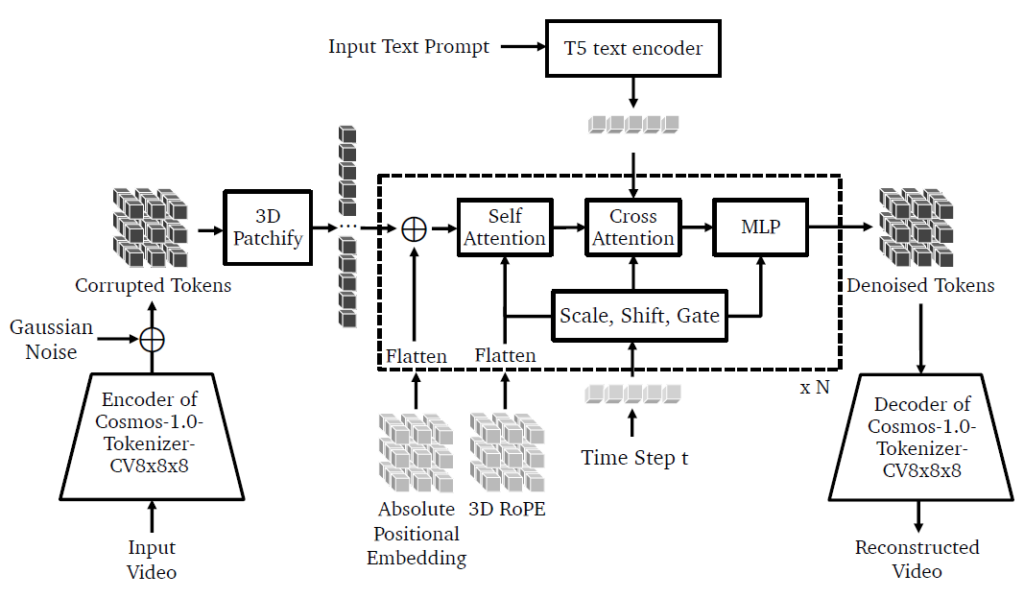
- Advanced Diffusion Models: Cosmos diffusion models, trained to progressively remove noise from data, are tailored for physical AI development with features such as 3D patchification, hybrid positional embeddings, cross-attention layers, and adaptive layer normalization with LoRA, enabling high-quality, physics-aware video generation.
- Customizable Guardrails for Safety: Cosmos prioritizes responsible AI development. Its customizable, two-stage guardrail system includes a “Pre-guard” for blocking potentially harmful text prompts and a “Post-guard” for blocking harmful outputs, ensuring safe and reliable model deployment.
- Comprehensive Benchmarks for Evaluation: Cosmos benchmarks go beyond standard fidelity, temporal consistency, and speed metrics, introducing new dimensions to evaluate 3D consistency and physics alignment in generated videos, critical for accurate physical AI system development.
- Integration with NVIDIA Omniverse: This integration allows developers to generate tailored synthetic datasets by creating 3D scenarios in Omniverse and using Cosmos to generate photorealistic videos, enabling the development and evaluation of policy models and foresight for action selection.
- Two-Stage World Model Training: Cosmos introduces a two-stage approach to world model training, starting with generalist models pretrained on vast datasets covering real-world physics, which can then be fine-tuned into specialists for specific applications using smaller, targeted datasets, greatly reducing the required data and training time.
- Accelerated Data Processing: Cosmos features NVIDIA NeMo Curator, a data processing and curation pipeline optimized for NVIDIA data center GPUs, enabling efficient processing of vast video datasets for training, significantly reducing the time and resources needed for data preparation.
- High-Fidelity Compression and Reconstruction: Cosmos tokenizers, available for both autoregressive and diffusion models, excel in compressing and reconstructing data with faster speeds and higher quality, reducing costs and complexity in model training.
- Fine-Tuning with NVIDIA NeMo: The NVIDIA NeMo Framework accelerates model training by efficiently loading and processing multimodal data, enabling developers to fine-tune Cosmos world foundation models or build new ones on GPU-powered systems.
Three model sizes offered by NVIDIA Cosmos
NVIDIA Cosmos offers developers three distinct model sizes to cater to varying performance, quality, and deployment requirements:
- Nano: These models are optimized for real-time, low-latency inference and edge deployment. They prioritize speed and efficiency, making them suitable for applications where rapid processing and minimal delay are crucial.
- Super: These models are designed as performant baseline models, providing a balance between performance and quality. They offer a solid foundation for various applications without requiring the highest level of fidelity or computational resources.
- Ultra: These models are focused on achieving maximum quality and fidelity. They excel in generating high-detail, realistic outputs, making them ideal for tasks where visual accuracy is paramount, such as distilling custom models or creating high-fidelity simulations.
Cosmos’s guardrail system for safe AI use:
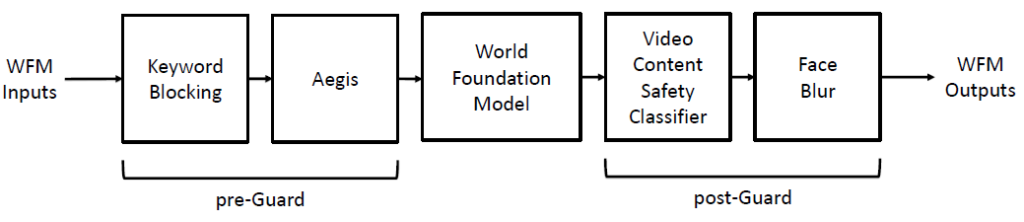
Cosmos guardrail operates in two stages: a pre-guard stage that filters potentially harmful input prompts and a post-guard stage that scrutinizes and filters the generated outputs.
Pre-Guard: This stage employs two layers of protection:
- Keyword Blocking: This mechanism acts as the first line of defense. It scans input prompts for unsafe keywords using a pre-defined blocklist. The system lemmatizes input words to detect variations, including non-English terms and misspellings, ensuring comprehensive screening. If a match is found, the entire prompt is rejected, preventing the generation of potentially harmful content.
- Aegis Guardrail: This layer provides a more nuanced analysis of the input prompt. It utilizes the NVIDIA fine-tuned Aegis AI Content Safety model to detect semantically unsafe prompts. This model has been trained on a vast dataset covering 13 critical safety risk categories, including violence, harassment, and profanity. If the model flags the prompt as unsafe, video generation is halted, and an error message is displayed to the user.
Post-Guard: This stage focuses on ensuring the safety of the generated video output. It comprises two key elements:
- Video Content Safety Classifier: This component examines every frame of the generated video for potentially unsafe content. A multiclass classifier, trained on a dataset that includes real videos, synthetic videos, and human-annotated data, evaluates each frame for compliance with safety guidelines. If any frame is flagged as unsafe, the entire video is rejected, ensuring a high standard of safety.
- Face Blur Filter: This filter is designed to protect privacy and mitigate biases. It utilizes the RetinaFace model to detect human faces in the generated videos and automatically blurs them.
Red Team Testing and Refinement: To rigorously test the effectiveness of the guardrail system, NVIDIA employs a dedicated red team that actively probes the system with both standard and adversarial examples. These tests cover a wide range of potential scenarios and edge cases, ensuring that the guardrail system remains robust. The team annotates over 10,000 prompt-video pairs to identify any weaknesses and improve performance, particularly in challenging situations.
NVIDIA NeMo Curator employs several strategies to drastically accelerate data processing, achieving speeds up to 89 times faster than traditional CPU-based methods. Here’s how it works:
- GPU Optimisation: NeMo Curator is specifically designed and optimised to leverage the parallel processing power of NVIDIA data centre GPUs. This allows for significant acceleration compared to CPU-based pipelines which struggle with the computational demands of video data.
- Hardware Acceleration: NeMo Curator utilises hardware-accelerated video encoding and decoding capabilities present in modern GPUs like the NVIDIA L40S. This significantly boosts the speed of video processing tasks.
- Efficient Software Configuration: NeMo Curator incorporates efficient software settings, including switching from the libx264 codec to the hardware-accelerated h264_nvenc codec, and processing multiple clips from the same video in batches. This further enhances the throughput of the data processing pipeline.
- PyNvideoCodec Integration: NeMo Curator leverages PyNvideoCodec for video stream transcoding instead of relying solely on ffmpeg. This results in much higher utilisation of the GPU’s NVDEC/NVENC accelerators, leading to substantial gains in processing speed.
- Parallel Processing with Ray: The platform utilises the AnyScale Ray framework to implement a streaming pipeline system for data processing across geographically distributed clusters. This parallel processing approach ensures efficient resource utilisation and robust operation, even with high-latency connections to data sources.
Physical accuracy evaluation determines how well the dynamics rendered by Cosmos WFMs adhere to real-world physics. A suite of simulated 3D scenarios, encompassing various physical phenomena (gravity, collisions, momentum transfer), serves as ground truth. Pixel-level metrics (PSNR, SSIM), feature-level metrics (DreamSim similarity), and object-level metrics (IoU for tracked objects) are employed to compare the generated videos with the physically accurate simulations, providing a comprehensive assessment of the model’s fidelity in simulating real-world physics.
Cosmos WFMs can generate consistent and synchronized videos from multiple viewpoints, enabling realistic and immersive simulations. Specialized models are trained on datasets containing multi-view video sequences, such as the Real Driving Scene (RDS) dataset, which encompasses six camera views from a driving platform. These models utilize view-independent positional embedding and view-dependent cross-attention mechanisms to account for varying viewpoints, ensuring coherence across generated views.
Overall, Cosmos represents a significant advancement in the field of physical AI. By providing developers with the tools and resources to create and deploy world foundation models, NVIDIA is paving the way for the development of more intelligent and capable autonomous systems.
Resources

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!