Chatbots produce text. Agents produce outcomes.
The conceptual shift is simple: instead of stopping at an answer, an AI agent keeps going. It searches, clicks, writes code, calls APIs, checks whether the result is correct, and repeats until a goal is reached (or it is forced to stop by policy, budget, or human oversight).
This article is a practical, engineering-first guide to agentic systems. It covers the core loop, the common control patterns, what differentiates a single agent from an agentic system, and what reliability and safety look like in practice.
Quick Takeaways
- An AI agent is a system that perceives its environment, makes decisions, takes actions using tools, and evaluates outcomes to achieve a goal. AI Agents evolve LLMs from text generators into autonomous systems.
- Core Loop: Unlike rigid automation, agents operate probabilistically: Observe $\rightarrow$ Decide $\rightarrow$ Act $\rightarrow$ Evaluate. They adapt to feedback and recover from errors.
- System vs. Solo: A single Agent handles a task (like a thermostat), while Agentic AI orchestrates multiple agents and shared state (like a smart home system).
- Key Components: The LLM is the brain, but the body requires Tools (interfaces), Memory (state), Guardrails (safety), and Planning mechanisms (like ReAct or Tree Search).
- Engineering First: Building agents is less about prompting and more about workflow design, state management, and evaluation to ensure reliability and safety in production.
What Is an AI Agent?
An AI agent is a system that:
- Observes an environment (APIs, files, a browser, a UI, sensors)
- Chooses actions to accomplish a goal
- Executes actions through tools
- Uses outcomes to update what it does next
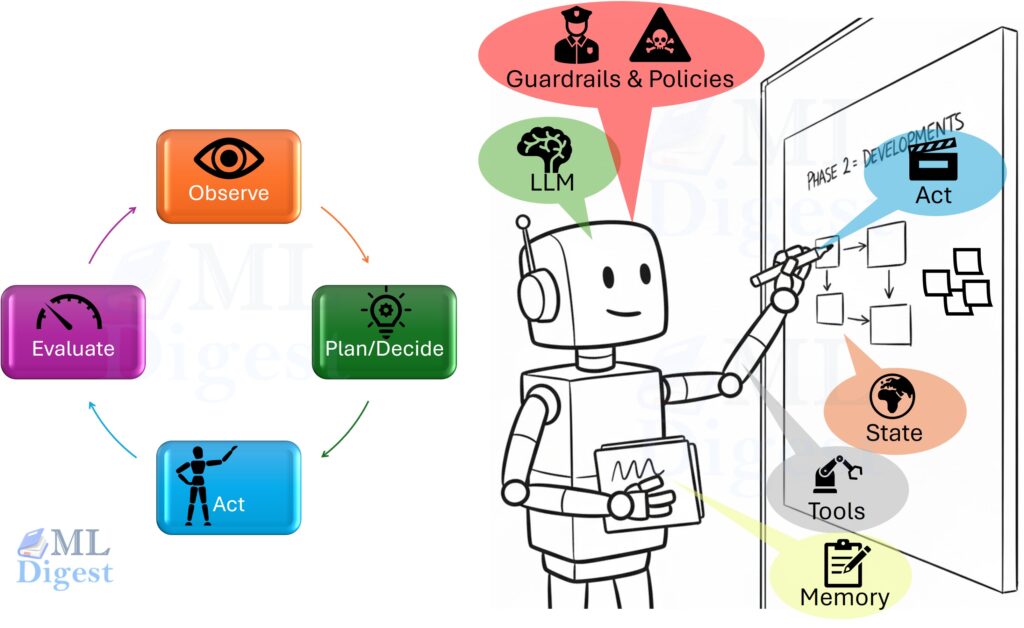
Most modern agents are LLM-centered: a large language model (LLM) acts as the decision engine over the current state. However, the LLM is not the whole system. The engineering around it matters just as much:
- Tools: what actions are possible (and with what permissions)
- State: what the agent currently believes and remembers
- Memory: what is persisted across steps or sessions
- Guardrails: what is allowed, what requires approval, and what is blocked
Add one that teams often forget until things break:
- Evaluation: how the system decides it is done (or not done)
Agent, workflow, and automation: a useful distinction
In practice, many systems that people call “agents” are one of these:
- Workflow automation: fixed steps (deterministic control flow). Reliable, limited.
- Tool-using assistant: chooses among tools, but within a narrow sandbox.
- Agent: has a feedback loop and can recover from failures by changing strategy.
The more autonomy you add, the more you must invest in guardrails, evaluation, and observability.
The Core Loop
At its heart, every agent implements a control loop:
- Observe: Gather state relevant to the goal (user input, files, API responses).
- Decide/Plan/Think: Choose a next action (or a short plan) given the state and the goal.
- Act: Call a tool (search, database, code execution, UI action).
- Evaluate: Check what happened; update state; continue or stop.
This repeats until the goal is achieved, a stop condition triggers (budget/time), or the agent escalates to a human.
Design tip: define how success is checked (and by whom). If evaluation is implicit, the agent will stop early, stop late, or oscillate.
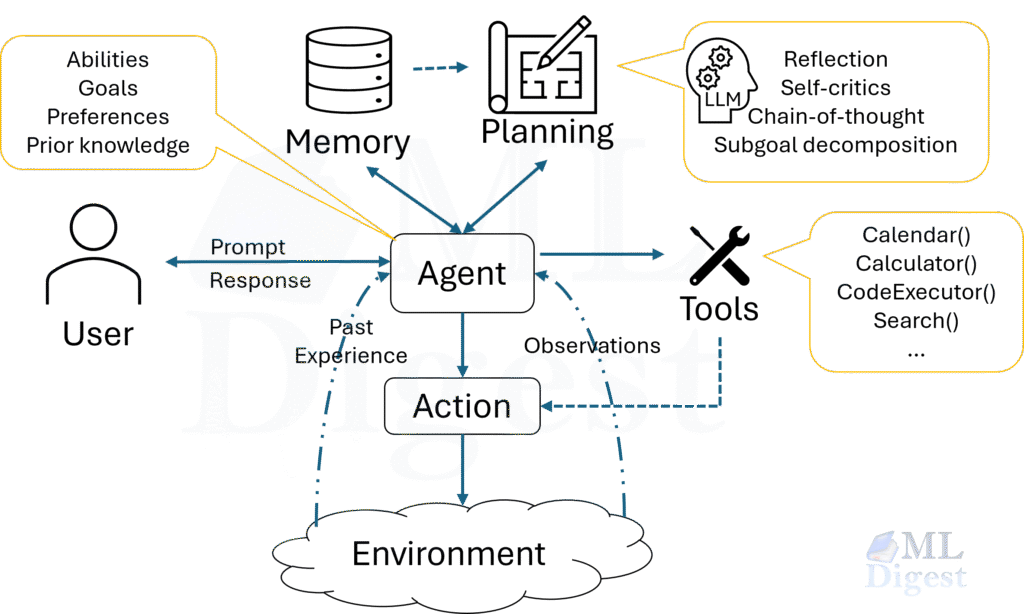
A simple mental model of agent state
Agent behavior is less about prompt wording and more about state and control:
- Goal state: what success means (ideally measurable)
- World state: what the agent believes is true right now
- Action history: tools called, inputs/outputs, and decisions
- Constraints: cost, latency, permissions, and policy restrictions
Add two more that matter in production:
- Stop conditions: maximum iterations, timeouts, budget, “no progress” detectors
- Verification results: what checks have passed or failed
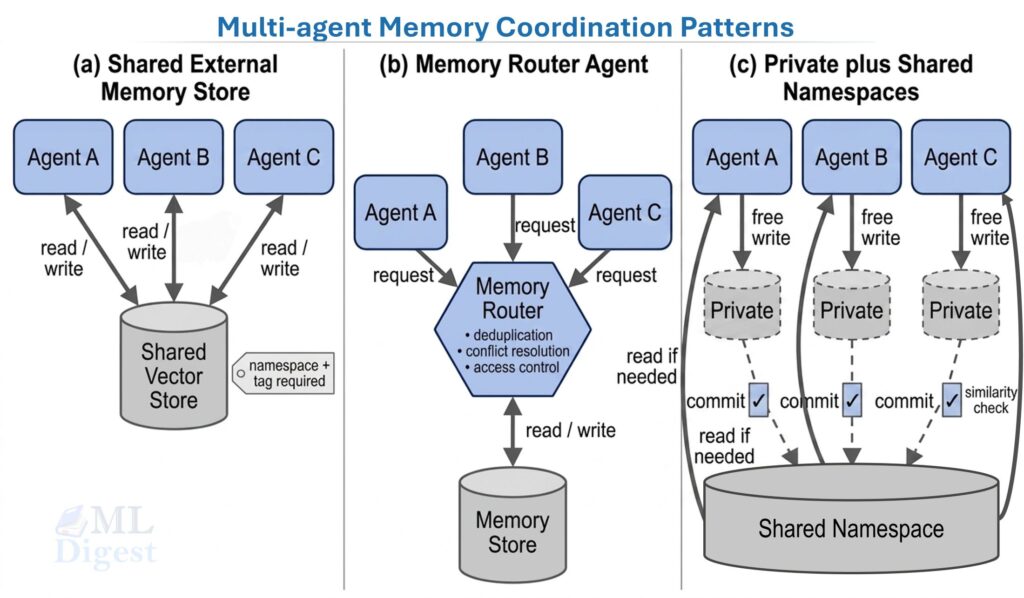
Memory: short-term, episodic, semantic
Agent “memory” is often discussed vaguely. It helps to separate it:
- Short-term memory: the current context window (messages + current state).
- Episodic memory: logs of prior runs (what was tried, what happened).
- Semantic memory: facts and documents stored for retrieval (vector DB, search index).
The reliability question is not “does the agent remember?” but “does memory improve success without creating stale beliefs?” Stale memory is a common cause of tool misuse and wrong plans.
The Three Core Characteristics of AI Agents
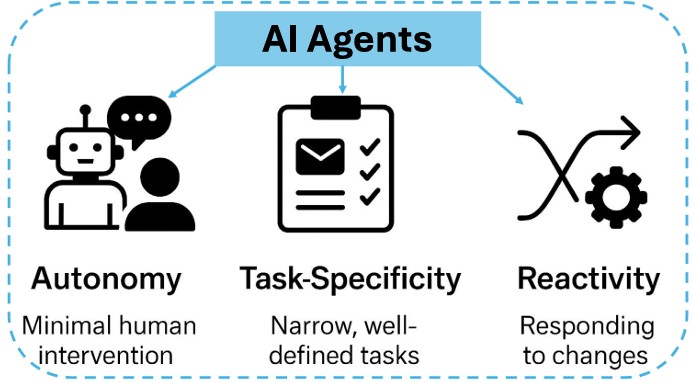
 (Image depicting the three core characteristics of AI agents: Autonomy, Task-Specificity, and Reactivity and Adaptation. Source: Paper)
(Image depicting the three core characteristics of AI agents: Autonomy, Task-Specificity, and Reactivity and Adaptation. Source: Paper)
AI agents differ from traditional software in a few practical, engineering-relevant ways.
Think of classical software like a toaster: if you press the lever, it runs the same cycle. An LLM-based agent is more like a chef following a goal, figuring out the recipe, checking the pantry, tasting, and adjusting on the fly.
Three traits that tend to matter operationally are:
- Autonomy (The “Self-Starter”):
Agents operate with minimal human intervention. Once you initialize them, they perceive their environment, reason over context, and execute actions in real-time. This autonomy allows them to scale in places where “human-in-the-loop” oversight isn’t practical, such as handling 24/7 customer support or managing complex scheduling. - Task-Specificity (The “Specialist”):
While generic LLMs are “jacks of all trades,” effective agents are often purpose-built for narrow, well-defined tasks. They are optimized to execute repeatable operations—like filtering emails, querying databases, or coordinating calendars. This focus allows for higher efficiency and precision than asking a general model to do everything. - Reactivity and Adaptation (The “Reflexes”):
The real world is dynamic. Agents are designed to interact with changing inputs, responding to real-time stimuli like a user changing their mind or an API returning an error. Through feedback loops and updated context buffers, they refine their behavior over time, ensuring they can navigate a fluid environment rather than just following a rigid script.
How Agents “Think”: Common Reasoning Patterns
Different tasks call for different control flows. The key distinction is whether you interleave decisions with tool results, and how you recover when the environment is unpredictable.
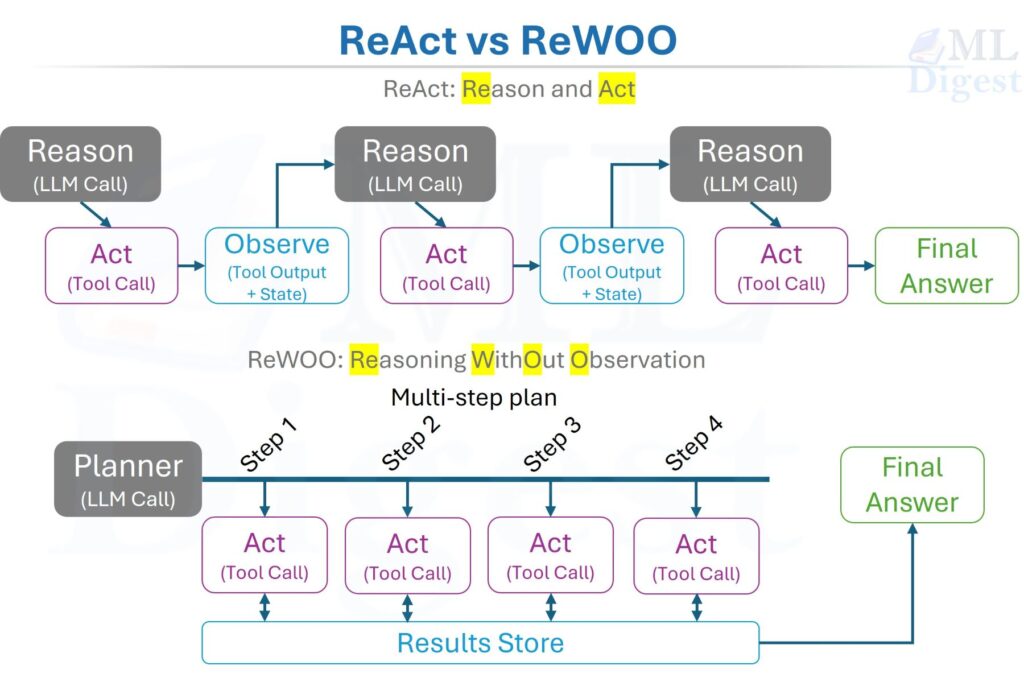
ReAct (Reason + Act)
ReAct interleaves decisions and actions: decide → act → observe → decide again.
In production, you often do not want to expose chain-of-thought. Instead, use structured tool calls plus a short rationale and visible progress indicators.
Example (conceptual):
- Decide it needs current info → call web search
- Read results → extract the answer
- Verify key facts → respond
Plan-then-execute (ReWOO-style)
Plan a sequence first, then execute. This can reduce LLM calls and improve consistency, but it is less robust when the environment is unpredictable.
Good fit: tasks with stable steps (ETL pipelines, scheduled reports). Risky fit: browsing, form filling, flaky APIs.
Tree/Graph search (ToT-style)
Generate multiple candidate steps/solutions, evaluate, and explore. This can improve performance on tasks with deceptive dead ends (debugging, math, strategic planning), but it’s expensive and needs a scoring function.
AI Agents vs Agentic Systems: From Tools to Workflows
The terms “AI agents” and “agentic AI” are often used loosely. In practice, “agentic” describes a design pattern—systems that use tool-driven feedback loops and self-correction—rather than a specific software package.
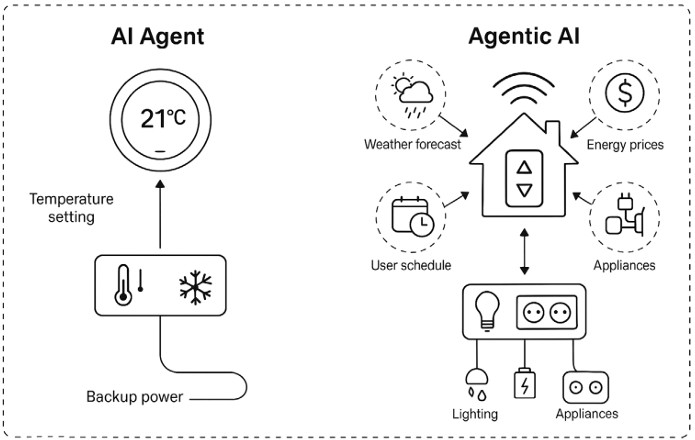
 (Illustrating the difference between AI Agents and Agentic AI, highlighting that AI Agents are single-entity systems focused on specific tasks, while Agentic AI encompasses multi-agent ecosystems with orchestrated collaboration and persistent memory. Source: Paper)
(Illustrating the difference between AI Agents and Agentic AI, highlighting that AI Agents are single-entity systems focused on specific tasks, while Agentic AI encompasses multi-agent ecosystems with orchestrated collaboration and persistent memory. Source: Paper)
To understand the difference, imagine a smart home. An AI Agent is like a smart thermostat. It has a specific job: it observes the room temperature, compares it to your setting, and turns the heater on or off. It is autonomous within its narrow domain, but it operates in isolation.
Agentic AI, on the other hand, is the entire home automation system. It coordinates the thermostat, the weather forecast, your calendar, and the electricity rates. It proactively cools the house before peak pricing hours because it “knows” you are coming home early. It represents a system-wide intelligence rather than a single task runner.
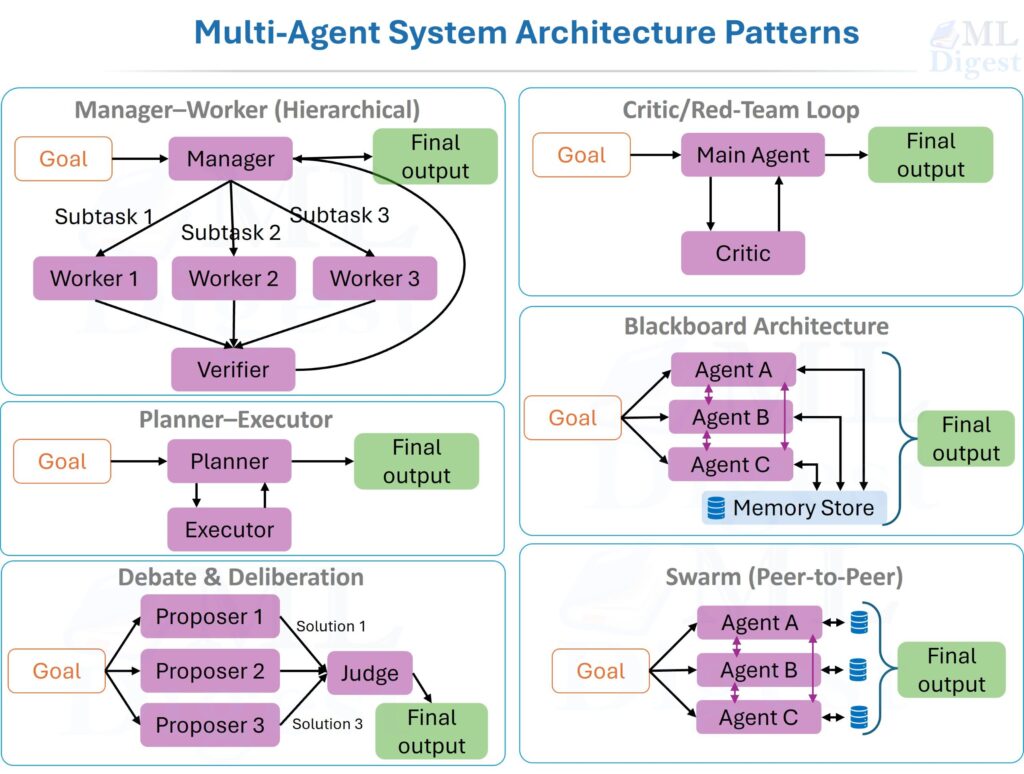
Architectural Distinctions: From Solos to Symphonies
At a structural level, the move from AI Agents to Agentic AI is a shift from individual modules to orchestrated ecosystems.
- Single-agent orchestration (The Soloist):
The architecture is often a single controller loop: “Observe $\rightarrow$ Decide $\rightarrow$ Act $\rightarrow$ Evaluate”. It may include retrieval and a state store, but control is centralized. - Agentic AI (The Orchestra):
This represents an orchestrated ecosystem. Key architectural enhancements include:- Orchestration Layers: “Meta-agents” or routers that manage the lifecycle of subordinate agents, delegating work and resolving conflicts.
- Multi-Agent Collaboration: A distributed intelligence where specialized agents (e.g., a “Researcher” and a “Writer”) communicate via message queues.
- Persistent Memory: Unlike the transient context of a single agent, agentic systems use episodic and semantic memory (often backed by Vector Databases) to preserve knowledge across different sessions.
Autonomy: Reactive vs. Proactive
The behavior of these systems also differs significantly.
- Bounded Autonomy (AI Agents): These are primarily reactive. You provide a prompt (“Book a meeting”), and they execute the function. They function well within fixed boundaries but struggle to recover from unexpected system states without human intervention.
- Coordinated Autonomy (Agentic AI): These systems are proactive. They can decompose high-level goals (“Plan a successful product launch”) into subtasks, prioritize them, and adapt to failures in real-time. If one agent fails effectively, the system can reroute the task to another.
Summary of Differences
| Feature | AI Agents | Agentic AI |
|---|---|---|
| Composition | Single-entity/Modular | Multi-agent/Orchestrated |
| Control Logic | Iterative loop (Prompt $\rightarrow$ Tool calls with feedback) | Orchestrated loops (routing, sub-tasks, and shared state) |
| Planning Horizon | Single-step or narrow | Multi-step and long-horizon |
| Initiation | Reactive (prompt-triggered) | Proactive (goal-initiated) |
| Memory | Short-term/Optional | Persistent/Shared context |
Key Components (What makes an agent work)
- LLM Backbone: The core model driving decisions and tool selection. Model choice affects capability, latency, and cost.
- Tools: The agent’s connection to the outside world. Tools are simply functions or APIs that the agent can call. Common tools include:
- Web search
- Code interpreters (for running Python, shell scripts, etc.)
- Database query engines
- APIs for other services (Jira, GitHub, etc.)
- Planning & Decomposition: The ability to break a large, ambiguous goal into a sequence of concrete steps. This is one of the most challenging aspects of agent design.
- State Management: Tracking progress, intermediate results, and action history (ideally in a structured state object).
- Guardrails: sandboxing, allowlists, rate limits, and human approval gates.
- Observability: logs, traces, and metrics for debugging behavior.
Add one that makes the difference between demos and production:
- Evaluation & Verification: checks that determine whether the goal is met (tests, schema validation, consistency checks, human review).
A minimal agent specification (what to write down first)
Before you build anything, write a one-page spec:
- Objective: what “done” means.
- Inputs/outputs: what the agent receives and produces.
- Allowed tools: read-only vs write vs irreversible.
- State schema: what variables exist (and their types).
- Stop conditions: max steps, timeout, budget, “no progress”.
- Verification: automated checks and human checks.
- Logging: what you will store for audits and debugging.
Types of Agents (Classic taxonomy, modern mapping)
Not all agents are created equal. Understanding the different types helps us choose the right architecture for the task at hand. The choice depends on the task complexity, the environment, and the level of autonomy required.
- Simple reflex agents: Hard-coded rules: “if condition, then action.” They react when certain conditions are met without considering past experiences or future implications. Useful for narrow automation, but brittle.
- Model-based reflex agents: Rules + an internal model that updates with observations. More sophisticated than simple reflex agents, these maintain an internal model of the world and consider both current perceptions and past experiences to make decisions. Their actions depend on their model, reflexes, previous percepts, and current state. They have memory and can operate in partially observable and changing environments. A robotic vacuum cleaner that adjusts its route based on detected obstacles while remembering cleaned areas exemplifies this type.
- Goal-based agents: Plans actions to reach a goal. These agents operate with a specific objective in mind. They can plan actions to achieve the desired goal, considering various scenarios and choosing the most effective approach. A navigation system that recommends the fastest route by evaluating multiple options demonstrates this type.
- Utility-based agents: Optimizes tradeoffs (time vs. cost vs. quality). Aiming to maximize a defined utility function, these agents consider not only goal achievement but also solution quality, choosing actions that provide the highest overall benefit based on pre-set criteria. A navigation system that factors in fuel efficiency, traffic conditions, and toll costs exemplifies this approach.
- Learning agents: Improve with experience (fine-tuning, retrieval updates, policy learning, preference models). The most advanced type, learning agents continuously adapt and improve their performance based on new experiences. They possess the capabilities of other agent types but can autonomously expand their knowledge base through feedback mechanisms. Personalized recommendation systems that track user activity to enhance suggestion accuracy illustrate this type.
Popular Agent Frameworks (and what they’re for)
Frameworks change fast; the useful question is what problem each solves.
- LangChain: broad components and integrations; good for quick prototypes.
- LangGraph: explicit state machines/graphs; good for production control flow.
- LlamaIndex: retrieval-heavy systems (RAG + tools), especially data access.
- AutoGen: multi-agent conversations and role-based orchestration.
- CrewAI: task/role orchestration with an opinionated API.
- Cloud platforms (e.g., Vertex AI): deployment, scaling, governance, monitoring.
If you’re choosing today: pick the smallest framework that gives you reliable tool calling, state, and observability.
Where Agents Go Wrong (and what to do about it)
If you build agents long enough, you’ll see a few repeated failure modes:
- Tool misuse: wrong arguments, wrong tool, or calling tools before gathering enough context.
- Mitigation: strict schemas, typed inputs, and better tool selection prompts.
- Infinite loops: retrying the same thing with no new information.
- Mitigation: loop detectors, max-iterations, and “try a different strategy” prompts.
- Hidden assumptions: the agent assumes a file exists, an API is available, or credentials are present.
- Mitigation: explicit environment checks and “confirm prerequisites” steps.
- Bad stopping: the agent thinks it’s done but outputs something unusable.
- Mitigation: verification step + measurable acceptance criteria.
Reliability checklist (production)
- Idempotency: retrying a tool call does not corrupt state.
- Timeouts + backoff: every external call has a deadline and a retry strategy.
- Circuit breakers: stop calling a failing dependency; degrade gracefully.
- Progress signals: track whether each loop iteration added new information.
- Deterministic validators: whenever possible, validate outputs with code (schemas, tests, linters).
This is why good agents look more like workflows with autonomy than free-form chat.
Building a Simple Agent (Python + CrewAI)
Below is a minimal multi-agent example. Treat it as a learning scaffold, not a production template:
- Don’t hard-code keys in code; use environment variables.
- Prefer “read-only” tools first (search, retrieval) before “write” tools (files, shell).
- Add a success check (did we actually produce the expected output?)
Install the libraries:
pip install crewai crewai_tools
from crewai import Agent, Task, Crew
from crewai_tools import SerperDevTool
# You'll need a SERPER_API_KEY for the search tool
# You can get one from https://serper.dev
# You'll also need an OPENAI_API_KEY
import os
# Do not hard-code API keys in code.
# Set these in your shell environment instead.
# Windows PowerShell example:
# $env:SERPER_API_KEY = "..."; $env:OPENAI_API_KEY = "..."
# Define the agents
researcher = Agent(
role='Senior Research Analyst',
goal='Uncover cutting-edge developments in AI and data science',
backstory="""You work at a leading tech think tank.
Your expertise lies in identifying emerging trends.
You have a knack for dissecting complex data and presenting actionable insights.""",
verbose=True,
allow_delegation=False,
tools=[SerperDevTool()]
)
writer = Agent(
role='Tech Content Strategist',
goal='Craft compelling content on tech advancements',
backstory="""You are a renowned Content Strategist, known for your insightful and engaging articles.
You transform complex concepts into compelling narratives.""",
verbose=True,
allow_delegation=True
)
# Define the tasks
task1 = Task(
description="""Conduct a comprehensive analysis of the latest advancements in AI in 2024.
Identify key trends, breakthrough technologies, and potential industry impacts.""",
expected_output="A full analysis report in markdown format.",
agent=researcher
)
task2 = Task(
description="""Using the research analysis, write a compelling blog post that highlights the most significant AI advancements.
Your post should be informative yet accessible, catering to a tech-savvy audience.
Make it sound cool, avoid complex words so it doesn't sound like AI.""",
expected_output="A full blog post of at least 4 paragraphs in markdown format.",
agent=writer
)
# Form the crew
crew = Crew(
agents=[researcher, writer],
tasks=[task1, task2],
verbose=2 # Set to 1 or 2 for different levels of logging
)
# Kick off the work
result = crew.kickoff()
print("######################")
print(result)This code sets up a two-agent crew: one to research and one to write. The crew.kickoff() method starts the process.
Note: whether this resembles “ReAct” depends on the framework version and configuration. Many frameworks implement tool-using loops, but the exact prompting and control logic differ.
A safer production shape (pseudocode)
If you want a mental template for production, use a single-agent loop with explicit state and validation. Think of it as an orchestrator around tool calls:
state = {
goal,
constraints,
scratchpad,
artifacts,
tool_history,
verification_results
}
for step in 1..MAX_STEPS:
observation = gather_context(state)
action = policy_guard(LLM(observation, state))
tool_result = call_tool(action)
state = update_state(state, tool_result)
if verify(state):
return success
if no_progress(state) or budget_exceeded(state):
return fail_or_escalateThe key idea is that the loop is a program. The LLM is only choosing actions inside it.
What to add for production
- Tool schemas + permissions: allowlists for domains/endpoints; least-privilege credentials.
- Retries + backoff: handle flaky networks and rate limits.
- Budgeting: max tool calls, max tokens, max wall-clock time.
- Verification: automated checks that output matches requirements.
- Audit logging: store tool inputs/outputs and user-visible results.
Real-World Applications and Use Cases
AI agents are already transforming industries across the spectrum:
- Customer Service: Providing 24/7 support, personalizing interactions, and resolving issues efficiently without human intervention for routine queries.
- Healthcare: Assisting with diagnosis, treatment planning, personalized patient care, and analyzing medical records to identify patterns.
- Finance: Detecting fraud in real-time, providing personalized financial advice, automating trading strategies, and processing insurance claims.
- Retail: Personalizing shopping experiences, recommending products based on behavior, managing inventory, and automating customer service tasks.
- Manufacturing: Optimizing production processes, predicting maintenance needs before failures occur, and enabling autonomous operation of machinery.
- Transportation: Powering self-driving vehicles, optimizing logistics and delivery routes, and managing traffic flow in smart cities.
- Software Development: Assisting with code generation, automated debugging, test creation, and code reviews.
If you’re looking for a fast starting point, pick one workflow where:
- Inputs are well-defined (a ticket, a document, a form)
- The agent can use mostly read-only tools
- Success is easy to verify (a compiled report, a test passing, a completed checklist)
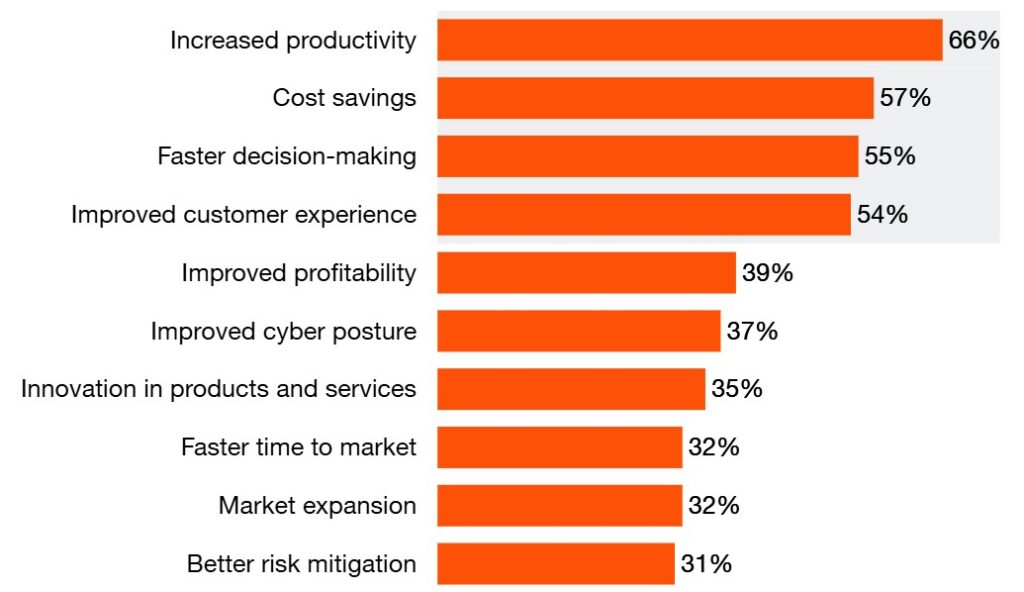
Why Enterprises Are Betting on AI Agents
Beyond the technical capabilities, AI agents deliver tangible business value:
- Enhanced Efficiency and Productivity: AI agents work tirelessly, 24/7, automating repetitive tasks and significantly boosting productivity. This allows human employees to focus on strategic, creative, and higher-value work. For example, agents can process insurance claims, gather financial data, or analyze marketing campaigns, freeing teams for complex problem-solving and customer interaction.
- Improved Customer Experience: Agents deliver faster, more personalized, and consistent customer service. They can answer queries, resolve issues, and provide tailored recommendations instantly, enhancing satisfaction and loyalty. This is especially valuable in industries with high customer interaction volumes like retail, finance, and support.
- Scalability and Cost Reduction: AI agents scale effortlessly to handle growing workloads and fluctuating demand. They manage high volumes of interactions and process large datasets without requiring proportional increases in human resources, leading to significant cost savings.
- Data-Driven Insights and Decision-Making: Agents analyze vast amounts of data to identify patterns and trends invisible to humans, providing valuable insights for informed decision-making. This data-driven approach enhances business strategies, improves operational efficiency, and enables proactive responses to market changes.
- Innovation and New Opportunities: By automating complex processes and creating new efficiencies, AI agents open opportunities for novel products and services. They can accelerate software development, optimize logistics, or personalize marketing at scale, driving business growth and competitive advantage.
Implementing AI Agents: A Practical Guide
For organizations looking to deploy AI agents, here’s a structured approach:
- Define Clear Objectives:
Establish well-defined objectives for your AI agents before starting implementation. Determine specific goals: reducing response times, improving customer satisfaction, automating tasks, or gaining data-driven insights. This clarity guides your implementation strategy and enables success measurement. - Assess and Prepare Your Data:
AI agents rely heavily on high-quality data. Ensure robust systems for data collection and management from customer interactions, transaction histories, and other relevant sources. Clean, structured, and unbiased data is essential for accurate and relevant agent responses. - Choose the Right AI Agent Type:
Select the most suitable agent type for your needs. For straightforward tasks like routine customer queries, a simple reflex or goal-based agent might suffice. Complex scenarios may require utility-based or learning agents that adapt to dynamic situations. - Integrate with Existing Systems:
Ensure seamless integration with current CRM, customer service tools, and other relevant systems. This integration allows smooth information flow, enabling agents to access comprehensive and up-to-date data for enhanced performance. - Focus on User Experience:
Design agents with a user-centric approach. Interactions should be intuitive, responses prompt and accurate, and aligned with your brand’s voice. Thoroughly test agents to identify and rectify issues before deployment. - Monitor and Optimize:
Continuous monitoring and optimization are vital for sustained effectiveness. Regularly assess performance, gather user feedback, and analyze operational data. Use these insights to make adjustments, refine algorithms, and adapt to evolving needs. - Plan for Human Oversight:
While agents handle many tasks autonomously, have provisions for human intervention when needed. Establish clear guidelines for when and how human agents step in, particularly for complex or sensitive interactions. - Ensure Data Privacy and Security:
Implement robust data privacy and security measures when handling customer information through AI agents. Comply with data protection regulations and conduct regular security audits to safeguard sensitive data and maintain trust. - Define permissions and approval gates:
Decide which actions an agent can take without approval. A common pattern:- Read-only actions: safe by default (search, retrieval, analytics queries)
- Write actions: require stronger controls (file writes, sending emails, posting to APIs)
- High-risk actions: always require human approval (payments, user management, deletion)
- Instrument everything:
If you can’t observe it, you can’t improve it. Capture:- Tool calls (inputs/outputs)
- Latency and cost
- Failures and retries
- Final outcomes against success criteria
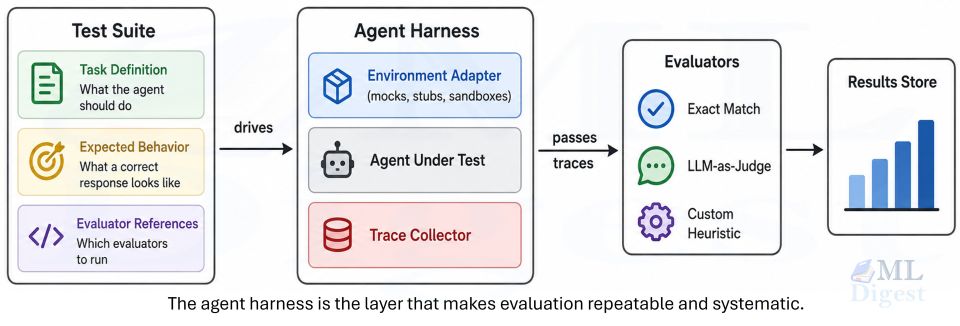
Evaluating AI Agents: How Do We Measure Intelligence?
Building an agent is easy; knowing if it works is hard. Traditional text-overlap metrics (BLEU/ROUGE) are usually misaligned for agentic tasks. Instead, you typically evaluate task success, cost/latency, and failure modes (including safety).
A simple scoring function (useful for search-style agents)
When you use tree/graph search, you need a score. In practice, a weighted score often works well:
$$
\text{score} = w_1 \cdot \mathbb{1}[\text{task passed}] – w_2 \cdot (\text{tool errors}) – w_3 \cdot (\text{steps}) – w_4 \cdot (\text{cost})
$$
Even if you do not run full search, writing down a score like this forces clarity: what do you reward, what do you penalize, and what is considered “done”?
- GAIA (General AI Assistants Benchmark): A rigorous benchmark that tests an agent’s ability to solve complex tasks requiring reasoning, tool use, and multi-modality. It is considered one of the hardest tests for current agents.
- SWE-bench: Specifically designed for coding agents, this benchmark asks agents to resolve real-world GitHub issues in popular Python repositories.
- AgentBench: A comprehensive framework evaluating agents across multiple environments (OS, Database, Knowledge Graph, etc.).
Be careful with absolute statements like “hardest.” Benchmarks differ in coverage (tooling, time limits, contamination risk, scoring), so “hard” depends on the model and setup.
When building your own agents, define “pass/fail” criteria for every task. Did the file get created? Was the API called with the correct parameters?
Practical evaluation checklist
- Task success rate: % of runs that meet explicit criteria.
- Tool correctness: invalid tool calls, wrong arguments, permission violations.
- Efficiency: number of tool calls, latency, and cost per successful run.
- Robustness: performance under degraded conditions (timeouts, partial data).
- Safety incidents: prompt injection wins, data exfiltration attempts, unsafe writes.
Challenges and the Road Ahead
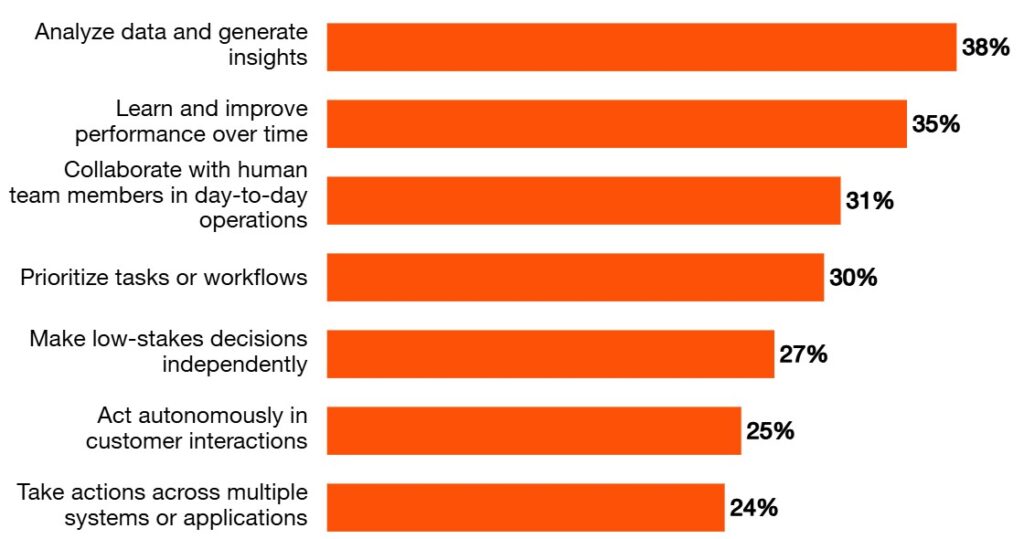
Agentic AI is still in its infancy, and significant challenges remain:
Technical Challenges
- Reliability and Action Hallucination: Unlike chatbots that hallucinate text, agents can hallucinate actions. An agent might try to call a non-existent API endpoint or delete a file it “remembers” incorrectly. They are also prone to getting stuck in loops, repeatedly trying the same failing action without changing strategy.
- Cost and Latency: The multiple LLM calls required for the thought-action loop can be slow and expensive. Each iteration of the ReAct loop requires API calls, which accumulate quickly in complex tasks.
- Long-Context Reasoning: Agents struggle with tasks that require maintaining a coherent plan over many steps or managing information that exceeds the LLM’s context window.
- Computational Complexity: Training and deploying sophisticated AI agents requires significant computational resources, making them inaccessible for smaller organizations or resource-constrained environments.
- Debuggability: The inherent unpredictability of AI models makes agents difficult to debug. Understanding why an agent made a particular decision or failed to complete a task can be opaque.
Safety and Ethical Concerns
- Safety and Security: A powerful agent with access to tools like a shell, file system, or database is a significant security risk. Preventing prompt injection attacks and ensuring agents don’t perform harmful actions is critical.
- Ethical Implications: Ensuring fairness, avoiding bias in decision-making, and mitigating potential negative consequences of autonomous actions requires careful consideration. Who is responsible when an agent makes a harmful decision?
- Data Privacy and Security: Protecting sensitive data used for training and operation, ensuring responsible data management practices, and complying with regulations like GDPR and CCPA is paramount.
- Human Oversight and Control: Defining appropriate levels of human intervention, ensuring responsible use, and maintaining human control over critical decisions remains a challenge as agents become more autonomous.
How to make agents safer in practice
Safety is mostly engineering discipline. A few patterns show up repeatedly:
- Least-privilege tools: split tools into read-only vs. write; require approval for writes/deletes.
- Allowlists: constrain browsers/search to approved domains; constrain APIs to known endpoints.
- Sandboxing: run code/tools in isolated environments; block access to local secrets by default.
- Input hardening: treat tool outputs and web content as untrusted (prompt injection is just untrusted input).
- Policy checks: run a separate “guard” step before executing high-risk actions.
- Human-in-the-loop: explicit confirmation for sensitive operations (payments, emails, file deletion).
- Observability: log tool calls, decisions, and final outputs; review incidents like any other system.
The Future of AI Agents
Despite these hurdles, the pace of innovation is staggering. The future of AI agents will be shaped by continued research and development in several key areas:
- Improving Reliability and Explainability: Enabling better understanding of how agents make decisions and increasing trust in their outputs through techniques like explainable AI (XAI) and better reasoning transparency.
- Developing More Sophisticated Reasoning and Planning: Allowing agents to tackle increasingly complex and dynamic problems through advances in multi-step reasoning, long-term planning, and contextual understanding.
- Enhancing Human-Agent Collaboration: Creating seamless and intuitive interfaces for humans to interact with and control AI agents, fostering a collaborative relationship rather than replacement.
- Addressing Ethical Concerns and Mitigating Risks: Developing guidelines, regulations, and technical safeguards for responsible AI agent development and use.
The successful integration of AI agents into society will require a collaborative effort involving researchers, developers, policymakers, and the public. By working together, we can harness the power of AI agents to create a future where technology augments human capabilities and contributes to a better world.
As models become more powerful and frameworks more robust, agents will move from novelties to indispensable tools for knowledge work, software development, and scientific discovery. They are not just another feature of AI; they represent a new paradigm for how we interact with and leverage computation itself—a shift from tools we use to partners that work alongside us.
Resources and Further Reading
- IBM: What are AI Agents?
- Maximilian Vogel’s Guide to Building AI Agents
- Salesforce: AI Agents and Agentforce
- Simform: Complete Guide to AI Agents

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!